
- はじめに
- 大規模言語モデル(LLM)とは
- データセットはどれくらい大規模なのか?|LLMのデータセットの大きさと構成。
- モデルはどれくらい大規模なのか?|LLMのモデルサイズ。
- なぜ「大規模」なのか?大規模化するメリット|スケールの法則とLLMの創発的能力。
- 言語モデルの仕組みは?|大規模言語モデルの特徴と共通点。
- 言語モデルはどのように発展してきたのか?|LLMまでの言語モデルの歴史。
- 言語学的・統計的アプローチ(1950年〜2000年)
- ニューラルネットワークによるアプローチ(2001年〜2017年)
- 大規模言語モデル・Transformerモデルによるアプローチ(2018年〜現在)
- LLMを理解するには、何から学べばよいのか?最短ルートは?
- おすすめの本・参考資料
- このサイト、Twitterについて
- 参照文献
はじめに
こんにちは!自然言語処理(NLP)・大規模言語モデル(LLM)の解説記事や書籍を書いている、
すえつぐです!
お知らせ:著書 『誰でもわかる大規模言語モデル入門』 を日経BPより出版しました。
今回は、大規模言語モデル(LLM)について解説していきます。
2022年末にChatGPTが発表されてから、大規模言語モデル(LLM)が大きな注目を集めています。急激に注目を集めているLLMですが、「LLMを上辺だけでなく、しっかり理解したい」という人も多いのではないでしょうか。
今後、ビジネス・研究でLLMの重要度は増していくでしょう。実際もう仕事・研究に利用している人も多いのではないでしょうか。
ただ、ちゃんとLLMを理解して使っている人は、ほんの一握りです。「よくわかってないけどLLMを使う人」と「LLMを理解して使う人」では、ビジネス・研究において、今後大きな差ができていくでしょう。
そこで今回は、LLMをしっかり理解するために、必須の基礎知識からLLMを徹底解説していきます。
もちろん、誰にでもわかるように難しい数式や図は使いません。図解を使ってわかりやすく解説していきます!
- LLMの知識があまりない人には入門記事として。
「流行ってるけど結局、LLMって何なのか?」
「LLMに興味を持った。でもこの分野には詳しくない。」という人向け。 - LLMの知識がある人には現状整理として。
「そろそろ一回、LLMの全体感を知りたい。現状を整理して欲しい。」という人向け。
今回の記事はNLPの基礎から最新情報まで網羅的にまとめます。急速に発展するLLMにおける全体感の整理にも役立ちます。
この解説記事を読めば、LLMを上辺だけでなく基礎から理解でき、今後のビジネス・研究にLLMをより活用できるようになるはずです。
大規模言語モデル(LLM)とは

ChatGPTを皮切りに、世界で注目を集める大規模言語モデル(LLM:Large Language Models)。
大規模言語モデルはその名の通り、大規模な言語モデルです。
具体的には、大規模なデータを学習することで、質問応答・翻訳・コード作成など様々なタスクを可能にしたモデルです。
代表的なモデルとしては、GPTモデルとPaLM(Googleが開発)が存在します。今流行のChatGPTもGPT-3.5・GPT-4を利用したアプリケーションです。また、GoogleのBARDもPaLM・PaLM2を元に開発されています。
この「大規模言語モデル(LLM:Large Language Model)」を理解するためには、「大規模(Large)」と「言語モデル(Language Model)」について、それぞれ理解していく必要があります。
そこで本記事では、以下のトピックを解説していきます。
大規模とは(LLMの「L」について解説)
①データセットはどれくらい大規模なのか?|LLMのデータセットの大きさと構成。
②データ・モデルを大規模にするメリット|大規模化による性能向上と、LLMの創発的能力。
言語モデルとは(LLMの「LM」について解説)
②言語モデルはどのように発展してきたのか?|LLMまでの言語モデルの歴史。
③LLMを理解するには、どの言語モデルから学べばよいのか?最短ルートは?
これらのトピックを理解すれば、LLMについて上辺だけでなく、より詳細に、体系的に学んでいけるでしょう。
データセットはどれくらい大規模なのか?|LLMのデータセットの大きさと構成。
大規模言語モデルの「大規模」とは、どれくらい大規模なテキストデータを使っているのでしょうか。またどのようなデータセットで構成されているのでしょうか。
この章ではLLMのデータセットの大きさと、それを構成するデータについて解説していきます。(主にGPTモデルを例に紹介していきます)
LLMのデータサイズ
LLMのデータセットは主に、ウェブテキスト(Wikipediaなど)、書籍、論文などで構成されています。
モデルによって、データセットのサイズ、構成は様々です。GPT-3は約3000億語1Brown, Tom, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D. Kaplan, Prafulla Dhariwal, Arvind Neelakantan et al. “Language models are few-shot learners.” Advances in neural information processing systems 33 (2020): 1877-1901.のテキストデータを学習していると言われています。
(*厳密には、データサイズは3000億トークンと公表されており、単純換算で3000億語と推定できますが、トークン化の方法によって異なります。)
3000億語と言われても実感がわきませんよね。3000億語は、文で考えると1500億文くらい、本で考えると400万冊くらいに相当します。本で400万冊となると、小さい図書館の蔵書数の約160倍に匹敵します。(高校にある図書館の蔵書数が平均2万5000冊くらいです2令和2年度「学校図書館の現状に関する調査」の結果について)
もはや人が一生で読める文字数を遥かに超えているのは確かです。
より詳細にGPTのデータサイズとその中身を見ていきましょう。
GPT-3の学習データのサイズと中身
データサイズ
GPT-3は3000億トークンのデータを学習しています。3OpenAI’s GPT-3 Language Model: A Technical Overview by Chuan Li。
データセットの中身
GPT-3 は、 Common Crawl4https://commoncrawl.org/、WebText25https://openwebtext2.readthedocs.io/en/latest/、Books1、Wikipediaなどの膨大な量のウェブテキストでトレーニングされています6Brown, Tom, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D. Kaplan, Prafulla Dhariwal, Arvind Neelakantan et al. “Language models are few-shot learners.” Advances in neural information processing systems 33 (2020): 1877-1901.。
Common Crawl・WebText2はウェブ上のテキストデータ、Books1・Books2はインターネットベースの書籍データです。

上の画像を見るとわかるように、GPT-1では本(Books)のデータのみだったのが、近年のGPT-2、GPT-3はより大規模に、より多用なデータセットを含むようになったことがわかります。
LLMが大量に学習する言語データ。この言語データが枯渇する可能性が報告されています。アバディーン大学とMITによる論文では、高品質な言語データは2026年以前に枯渇すると指摘されています。高品質な言語データが枯渇すれば、今後のLLMの大規模化は鈍化するかもしれません。
モデルはどれくらい大規模なのか?|LLMのモデルサイズ。
近年のモデルは、知的財産権や競争上の問題から、データセットのサイズや中身を公表しないケースが多くなっています。
一方で、モデルサイズを表すパラメータ数はほとんどの場合で公表されるため、パラメータ数を見てみましょう。*GPT-4などはパラメータ数も非公開
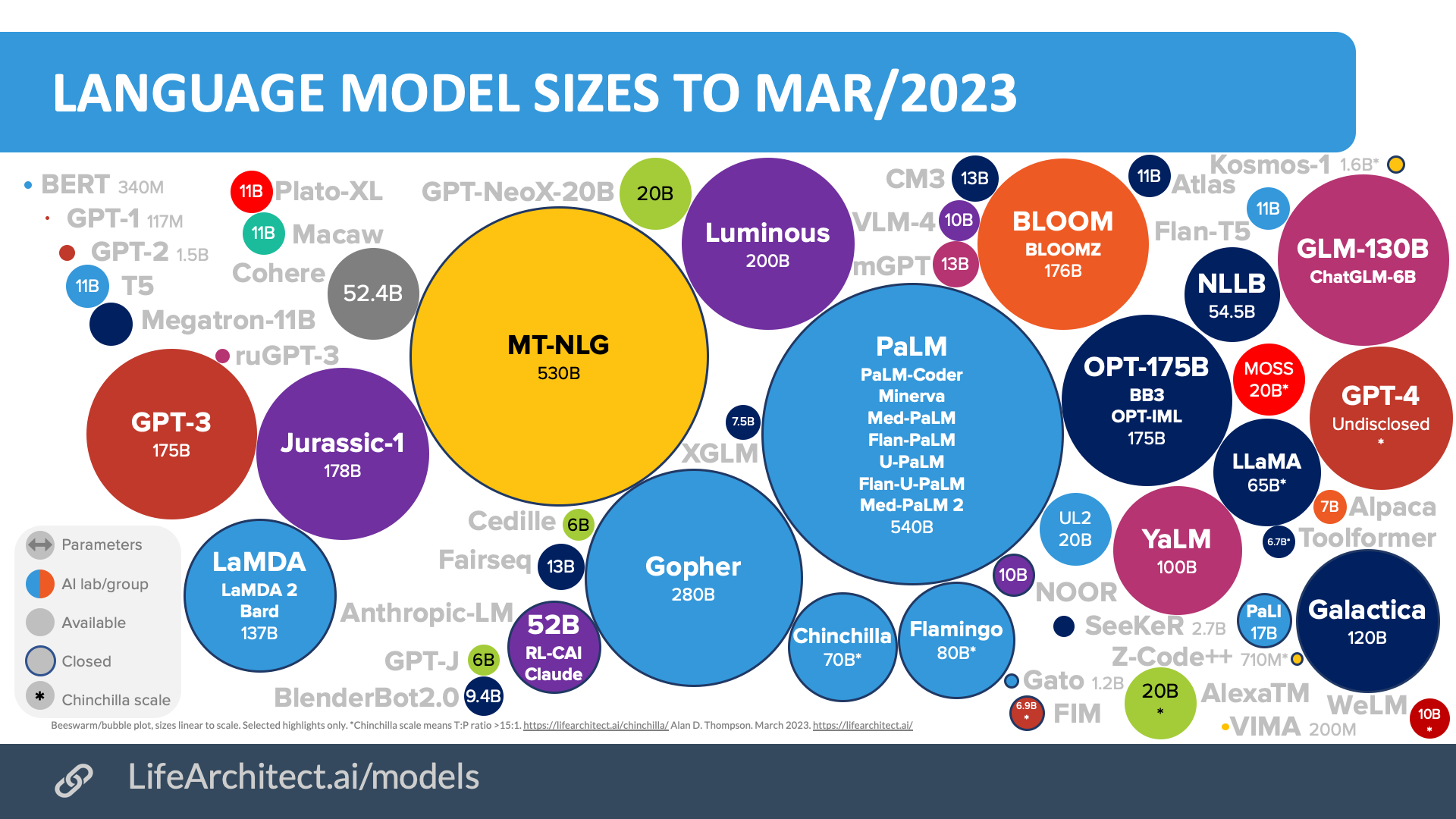
最新のモデルと比べると、2018年に公開されたBERT、GPT-1が見えないぐらい小さいことがわかります。近年の大規模言語モデルの「大規模さ」は飛躍的に増大しているのです。
冒頭では、LLMを「大規模な言語モデル」とざっくり紹介しました。
より厳密には、一般的に言語モデルの中でもパラメータが1000億を超えるモデルがLLMと呼ばれています7A Survey of Large Language Models(図の中で100B以上のモデル)。
そのため、パラメータが1000億を超えない事前学習モデルは、単に「事前学習モデル」と呼ばれます8A Survey of Large Language Models。BERT(3億パラメータ)やGPT-1(1億パラメータ),GPT-2(15億パラメータ)がこの事前学習モデルに当たります。
「なぜパラメータ1000億以上のモデルを”大規模言語モデル”と区別するのか?」と疑問を持った人もいると思います。
これは、パラメータが1000億を超えたGPT-3などから、それまでの小規模なモデルとは違う特殊な能力が見つかったからです。これについては次の章で詳しく説明していきます。
なぜ「大規模」なのか?大規模化するメリット|スケールの法則とLLMの創発的能力。
ここまではデータセットのサイズと中身について解説してきました。ここからは、データセット・モデルをなぜ「大規模」にする必要があるのか?解説していきます。
大規模にする理由は「LLMは大規模にすればするほど性能向上だけでなく、新しい能力も手に入れるから」です。
この「性能向上」と「新しい能力を手に入れる」についてそれぞれ説明していきます。
大規模化のメリット①大規模にすればするほど性能が上がる|スケールの法則
まず、性能向上に関しては、LLMにはスケールの法則(Scaling law)という法則が考えられています9Kaplan, Jared, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. “Scaling laws for neural language models.” arXiv preprint arXiv:2001.08361 (2020).。スケールの法則は、モデルサイズ、データサイズ、学習計算量を大きくすればするほどモデルの性能が上がるという法則です。
具体的には以下のグラフのように、モデルが一定以上大きくなると、急激に性能が向上します。計算タスク(左)、大学試験のスコア(中央)、文脈の意図を特定するタスク(右)で、一定のモデルサイズを超えた際に急激に性能向上していることがわかります。
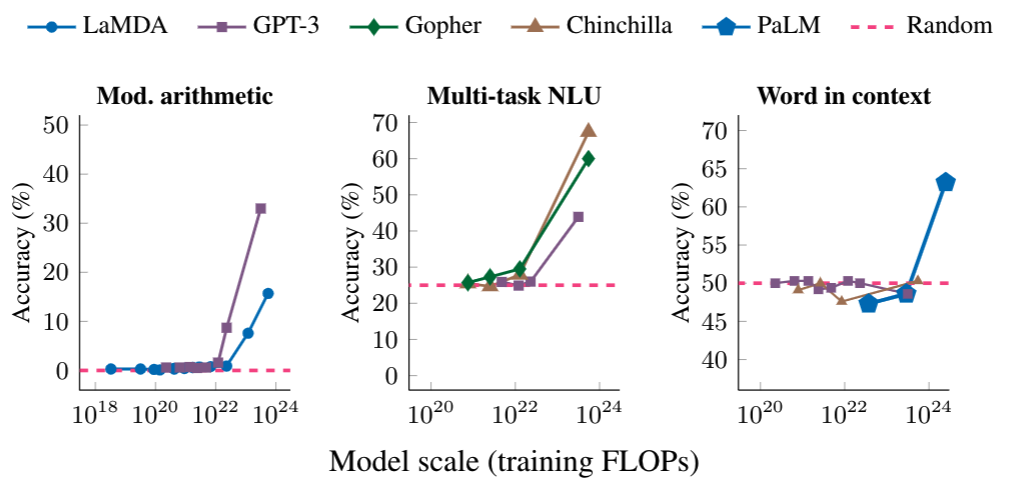
この法則が引き起こしたのは、資金力のあるIT企業がお金をかけてLLMをより巨大にするという現象です。
資金力のある企業からすれば「投資すれば性能が確実に向上する」ということがわかったら投資を惜しむはずがないですよね。実際に、巨大なモデルはほとんどがIT企業によって開発されています。
以下のLLMの進化過程を見るとわかるように、Google, Meta, OpenAI, DeepMindなどが競ってLLMを開発していることがわかります。
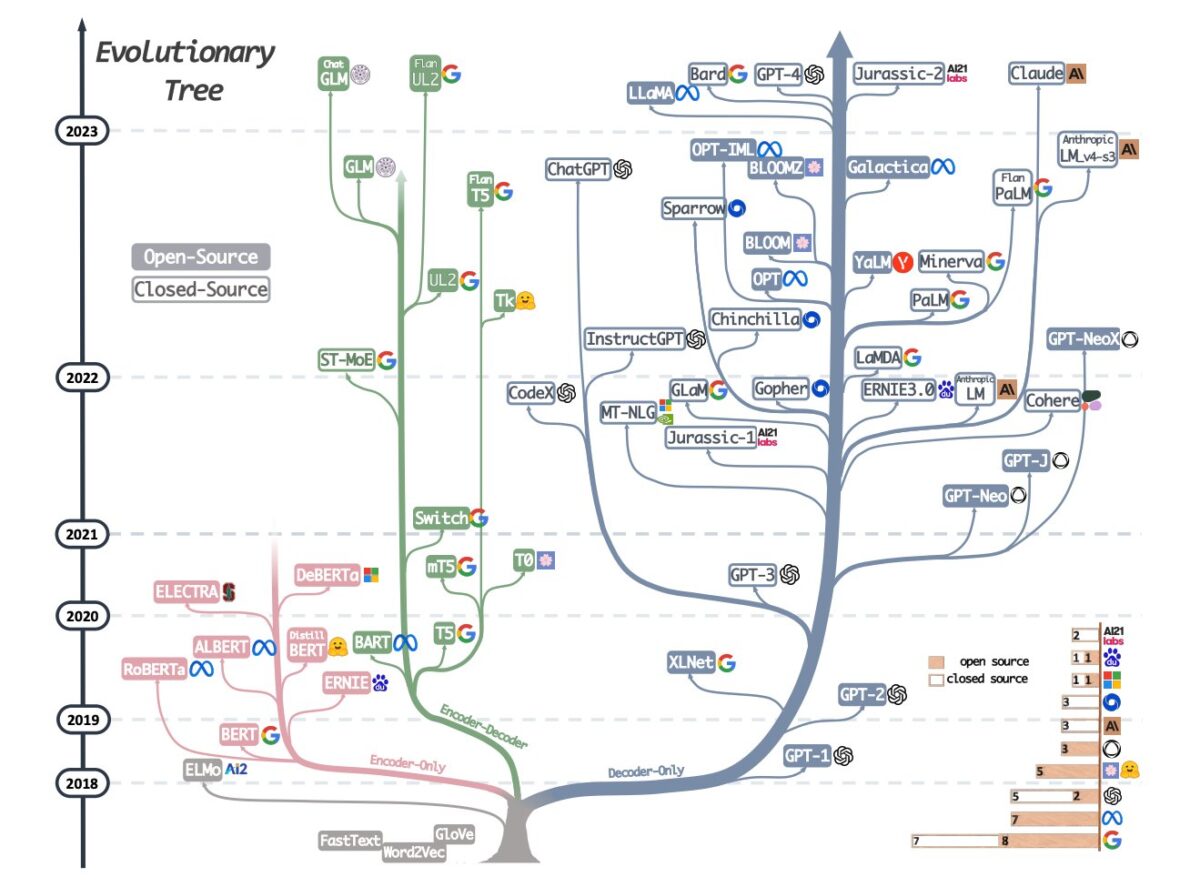
こういったスケールの法則、IT企業のLLM開発激化も、LLMが近年劇的に進化した一因です。
大規模化のメリット②大規模にすると新しい能力を手に入れる|創発的能力
小規模な言語モデルと比較して、大規模言語モデルは性能向上だけでなく、特別な能力を持ちます。この特別な能力が「創発的能力」と呼ばれています10Wei, Jason, Yi Tay, Rishi Bommasani, Colin Raffel, Barret Zoph, Sebastian Borgeaud, Dani Yogatama et al. “Emergent abilities of large language models.” arXiv preprint arXiv:2206.07682 (2022).。
創発的能力(Emergent abilities)とは
「創発的能力」とは、小規模モデルでは見られない能力であり、大規模言語モデル特有の能力です。
具体的には、「大規模化に伴って、それまでできなかった新しいタスクもできるようになる」というような現象が起きます。
大規模化に伴って、新たなタスクを解くことが可能になる
LLMが大規模になっていく過程で新たな能力が次々と発見されてきました。例えば、コーディングや数式の計算なども創発的能力によって獲得したLLMの能力です。
LLMのサイズと新たな能力は以下の様になっています。

この「大規模化に伴って新しい能力をどんどん手に入れていく」という創発的能力が生んだのが「超汎用的なモデル」です。
超汎用的なモデルとは、一つのモデルで、コーディング、翻訳、文章作成など様々なタスクを行うことができるモデルです。そう、ChatGPTです。ChatGPTやBARTのような超汎用的なモデルはこの創発的能力の恩恵を大きく受けています。
LLMが開発されるまでは、一つのタスクに一つのモデル、というのが当たり前でした。例えば、翻訳タスクには翻訳専用のモデルが作られていました。(Google翻訳やDeepLを想像してもらえるとわかりやすいです)
しかし、ChatGPTは翻訳・プログラミング・情報検索などの複数タスクを一つのモデルで実行できていますよね。
イメージとしては、従来は「AIが翻訳用の勉強をする→翻訳する」「コーディング用の勉強をする→コーディングする」という方法でした。
それに対してLLMの事前学習では「翻訳、コーディングを含む大量の文章を読んで、言語自体を理解する→翻訳もコーディングも何でもできる」というイメージです。
(先程紹介したように、LLMは事前学習で何百億語、何千億語というテキストを学習します。これによって言語自体の理解を可能にしています)
- LLMのデータセットはウェブデータ(Common Crawl, Wikipediaなど)や書籍データ(BookCorpusなど)で構成されている。
- 言語モデルは年々巨大化しており、特にパラメータが1000億を超える言語モデルが大規模言語モデル(LLM)と呼ばれるようになった。
- LLMが注目されている背景は、大規模にすればするほど性能向上する「スケールの法則」と大規模にすればするほど新しい能力が手に入る「創発的能力」があるから。
こういったLLMの急速な進化をキャッチアップするには、「LLMの基礎をある程度理解している」という状況を目指す必要があります。
「LLMをある程度理解する」ためには、本サイトのような入門記事を読むのに加えて、書籍を1−2冊だけでも読むことをおすすめします。おすすめ本に関しては以下の記事で厳選して紹介しています。

言語モデルの仕組みは?|大規模言語モデルの特徴と共通点。
ここまでは、LLM(大規模言語モデル)の「L(大規模)」について説明しました。
ここからはLLMの「LM(言語モデル)」の仕組みと開発の背景を解説していきます。まずはLLMの仕組みについて解説していきます。
LLMの仕組みはモデルによって異なりますが、共通するのはTransformerをベースとしたモデルであるということです。
実際に、GPTは「Generative Pre-trained Transformer」の略です。
今回はそれぞれのモデルの詳細な仕組みには踏み込まず、それぞれのモデルに共通する仕組みについて解説します。
LLMに使われている技術、どうやって作られているかはこの記事で解説しています。

LLMに共通する仕組み、Transformerアーキテクチャとは
前述の通り、LLMに共通する仕組みはTransformerアーキテクチャです。
このTransformerアーキテクチャがLLMに採用されている理由は、大きく2つの理由があります。
- 並列処理が可能。
→GPUの並列計算能力を使うことで、大規模なデータセットの高速な処理が可能に。 - 事前学習(Pre-training)と微調整(Fine-tuning)が可能。
→大量のテキストデータ(例えばインターネット上の文章)から共通の言語理解能力を学習することが可能に。
並列処理
並列処理とは、複数の計算を同時に行うことです。Transformerアーキテクチャでは、シーケンス内の全ての要素を一度に処理することができるため、GPUなどのハードウェアの並列計算能力を利用して、大規模なデータセットの高速な処理が可能になりました。
![]()
事前学習(Pre-training)と微調整(Fine-tuning)
事前学習とは、大量のテキストデータから言語そのものを学習するプロセスです。このプロセスでBERTでは33億語、GPT-3では3000億語学習していると言われています。
微調整は、事前学習の後、特定のタスク(例えば質問応答や感情分析)に対してモデルを最適化するプロセスです。事前学習で得た知識を利用して、微調整ではより少ないデータでも高い性能を達成することが可能になります。
この事前学習と微調整のプロセスは、人間の学習プロセスと似ています。人間も、高校まで色々な教科書や本を学び、大学からは専門的な内容を学びますよね。それによって仕事で専門的なタスクができるようになるわけです。
言語モデルもそれと同じで、事前に大量の文章を学んで、タスクごとにモデルを微調整するというプロセスを踏みます。事前学習は高校までの勉強、微調整は大学の勉強と考えるとわかりやすいかもしれません。
言語モデルはどのように発展してきたのか?|LLMまでの言語モデルの歴史。
ここまでは、LLMの概要と仕組みについて解説してきました。
更にLLMを理解するためには、BERTやGPTといったLLMのモデルを理解するのはもちろん、それらの背景を理解する必要があります。
ここからは、LLMの開発の背景、歴史を解説していきます。これはLLMの全体感の整理にもなります。これからLLMを学ぶ人にも、LLMを知っているが情報を整理したい人も必読です。
自然言語処理の歴史をざっくり解説
大きく分けて、これまでの自然言語処理の歴史は、以下のように3つの時代に分けられます。
1950年〜2000年|言語学的・統計的アプローチ(ニューラルネットを使わない時代)
2001年〜2017年|ニューラルネットワークによるアプローチ
2018年〜 現在 |大規模言語モデル・Transformerモデルによるアプローチ
言語学的・統計的アプローチ(1950年〜2000年)
言語学的・統計的アプローチ(1950年〜2000年)は、自然言語処理と機械翻訳の分野における初期の研究手法です。この時代は、現在の深層学習やニューラルネットワークが登場する前の、コンピュータ科学と言語学が交差する時期でした。以下は、この時代の主要な出来事や手法についての概要です。
この時代(1950年〜2000年)に生まれたいくつかの重要な技術と概念が、現在でも自然言語処理とLLMに大きな影響を与えています。
以下にこの時代におけるNLPの重要人物を解説します。
この時代は技術名でリストアップするのではなく、重要人物でリストアップしています。なぜなら、この時代に生まれたのは技術だけでなく、概念的に今のNLPを支えているものが多いからです。現在にも大きな影響を与えた重要人物を抑えることで、より効率的に理解できるはずです。
Noam Chomsky

構文理論と生成文法の父。1957年に出版された彼の著書「Syntactic Structures」は、構文解析の研究の基礎を築き、NLP分野に大きな影響を与えました。この著書は形態素解析技術の基礎となりました。
Zellig Harris
分布仮説を提案した1954年の論文「Distributional Structure」で知られます。この仮説は、単語の意味はその周囲の文脈によって決まるという考え方であり、現代の単語埋め込み技術や分布表現の基礎となっています。
Claude Shannon
情報理論の創設者。1948年の論文「A Mathematical Theory of Communication」で初めてN-グラムモデルについて言及しました。彼の業績は、NLPの統計的手法の基盤を築いたとされています。
他にも、単語の意味は使用法によって決まるという考え方を提案したJ.R. Firth、構文解析アルゴリズムの一つであるLR法を1973年に提案したDonald E. Knuth、構文解析アルゴリズムの一つであるEarley法を1978年に提案したJay Earleyといった方々も重要な人物です。
正直、この50年間の研究をひとまとめにすると怒られるかもしれません。ただ今主流のニューラルネットを使った手法とは大きく異るので、ここではひとまとめにさせていただきました。この時代の歴史を詳しく知りたい方はこの論文(英語)などを読んでみてください。
ニューラルネットワークによるアプローチ(2001年〜2017年)
2001年からはニューラルネットを使ったNLPモデルが研究され始めました。特に2013年ごろからRNNやLSTMといったディープラーニングの手法が開発され、新しい主流な手法となりました。

単語埋め込み・Word2Vec
単語埋め込みは単語を数値のベクトルで表現する方法です。Word2Vecはその一つで、周囲の単語の文脈を基に単語のベクトルを学習します。
RNN
RNNは時系列データに対する処理に適したニューラルネットワークで、過去の情報を保持し、次のステップに伝達する能力があります。

LSTM
LSTMはRNNの一種で、長い時系列データに対する情報の喪失問題を解決するために設計されました。これにより、長期間の依存関係を学習できます。
sequence-to-sequence(seq2seq)
seq2seqは一つのシーケンス(例えば、英語の文)を別のシーケンス(例えば、フランス語の文)に変換するモデルです。主に、機械翻訳などに使用されます。
Attention|Transformerの土台となる技術
Attentionメカニズムは、特定の情報に重点を置くことで、シーケンスの各部分をより効率的に処理する機能です。これにより、モデルは重要な情報に「注意(Attention)」を集中させることができます。

Transformer|LLMの土台となる技術
TransformerはAttentionメカニズムを基にしたモデルで、シーケンス内の全ての要素間の関係を同時に考慮します。機械翻訳や文章生成などのタスクで広く使用されています。このモデルは、GoogleのBERTやOpenAIのGPTなど、現代の多くの大規模言語モデルの基盤となっています。
この時代、機械学習・ニューラルネットによるNLPモデルのより詳細な歴史は、以下の記事でより詳細に解説しています。

大規模言語モデル・Transformerモデルによるアプローチ(2018年〜現在)
上の図が重要なTransformerモデルをまとめたものです。より詳細には、Transformerベースのモデルは非常に多くのモデルが開発されています。
より詳細に見ると以下のようになります。
上記のように、Transformerをベースとした事前学習モデルが急速に開発・発展してきました。
特に有名な事前学習モデルはGPTシリーズとBERTシリーズです。LLMを学ぶならまずGPTとBERTを学ぶのがおすすめです。
GPTシリーズ(GPT-1, GPT-2, GPT-3, GPT-4)
GPT(Generative Pretrained Transformer)は、OpenAIにより開発された大規模なトランスフォーマーベースの言語モデルシリーズです。
GPT-1からGPT-4までの各バージョンは、パラメータ数や訓練データの規模が増大しています。GPTは文章生成タスクに特化しており、大量のテキストデータから一貫性のある文章を生成する能力があります。
ChatGPT:GPTシリーズを活用したアプリケーション。
ChatGPTは、OpenAIのGPTシリーズをベースにした対話型AIです。ユーザーの質問やコメントに対して人間らしい応答を生成します。

BERT・PaLMシリーズ(両方ともGoogleによる開発)
BERT
BERTは、Googleが開発したTransformerベースのモデルで、最も有名な事前学習モデルです。BERTはテキストの両方向から情報を学習します。この双方向性が、特定のタスクに対する微調整時の性能を高めます。
PaLM
PaLM(Pathways Language Model)は、Google Researchが開発した5400億パラメータを持つ大規模言語モデルです。PaLM,PaLM2を元に、GoogleのAIチャットボット、BARTが作られています。
大きく分けると以下のような時代に分けられる。
1950年〜2000年|言語学的・統計的アプローチ(ニューラルネットを使わない時代)
2001年〜2017年|ニューラルネットワークによるアプローチ
2018年〜 現在 |大規模言語モデル・Transformerモデルによるアプローチ
LLMを理解するには、何から学べばよいのか?最短ルートは?
ここでは、「LLMを理解するには、何から学べばよいのか?」について解説していきます。
LLMを最短で学ぶには以下のような3つのステップで学ぶのがおすすめです。
【入門者・これから大規模言語モデル(LLM)を学びたい人はSTEP1から】
STEP1. 自然言語処理の入門書を読む
【中級者・LLMを体系的に学び直したいという人はSTEP2から】
STEP2. 機械学習・ディープラーニングの勉強・復習する
STEP3. LLMの理論と実装を、基礎から発展まで学ぶ
おすすめの本・参考資料
ここまでの学習、お疲れさまでした。そして本記事を最後まで読んでいただきありがとうございました!
ここからは、おすすめの書籍を紹介します。この記事で興味を持った方は、本を読めばさらに実践的な力が手に入るはずです。
特徴
・LLMの仕組みを、数式を使わず図で解説
・LLMを使った自動化をPythonコードで実装
今からLLMを体系的に学びたい、LLMを使った自動化や新機能を実装してみたいという方におすすめです。
以下のAmazon概要欄にて本の一部が無料で公開されていますので、ぜひ覗いてみてください。



おすすめの勉強ステップ
1. 概要・大枠を知る。
Webサイトなどで概要を理解する(本サイトはこのステップの支援を目指しています。)
詳細を学ぶ際に、より効率良くインプットできる。
2. 詳細を知る、理解を深める。
書籍、論文でより詳しく学ぶ。
3. 実践・アウトプット
SignateやKaggleに参加してモデルを作ってみる、勉強したことをブログにまとめる。
個人的には、データサイエンス、特にNLP関係の本は難しく、いきなり本を読むと挫折してしまう人が多いと感じています。
このサイトで概要・全体像を理解してから本を読むことで、より理解しやすく挫折も少なくなるはずです。(その役に立てるよう記事を執筆していきます!)

このサイト、Twitterについて
このサイトでは、NLP関係の解説記事をわかりやすく図解していきます。
「他のサイトの解説は難しすぎる」「もっと直感的に理解したい」という方々の役に立てるように解説していきます。
是非、お気に入り登録、Twitterのフォローをお願いします。Twitterでは、投稿のお知らせ、NLPの最新情報などを発信しています。
参照文献
論文
- Natural language processing: state of the art, current trends and challenges
- An overview and empirical comparison of natural language processing (NLP) models and an introduction to and empirical application of autoencoder models in marketing
- WHAT’S IN MY AI? by Alan D. Thompson LifeArchitect.ai March 2022
脚注参考文献
- 1Brown, Tom, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D. Kaplan, Prafulla Dhariwal, Arvind Neelakantan et al. “Language models are few-shot learners.” Advances in neural information processing systems 33 (2020): 1877-1901.
- 2
- 3
- 4https://commoncrawl.org/
- 5https://openwebtext2.readthedocs.io/en/latest/
- 6Brown, Tom, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D. Kaplan, Prafulla Dhariwal, Arvind Neelakantan et al. “Language models are few-shot learners.” Advances in neural information processing systems 33 (2020): 1877-1901.
- 7
- 8
- 9Kaplan, Jared, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. “Scaling laws for neural language models.” arXiv preprint arXiv:2001.08361 (2020).
- 10Wei, Jason, Yi Tay, Rishi Bommasani, Colin Raffel, Barret Zoph, Sebastian Borgeaud, Dani Yogatama et al. “Emergent abilities of large language models.” arXiv preprint arXiv:2206.07682 (2022).