
はじめに
こんにちは!自然言語処理(NLP)・大規模言語モデル(LLM)の解説記事や書籍を書いている、
すえつぐです!
お知らせ:著書 『誰でもわかる大規模言語モデル入門』 を日経BPより出版しました。
今回は、大規模言語モデル(LLM)の技術について解説していきます。
具体的には、「大規模言語モデルは、どんなステップで、どうやって作られているのか?」に沿って技術を解説します。LLMのアーキテクチャの解説から、LLMの学習方法など、ディープな内容をわかりやすく解説していきます。
なぜ大規模言語モデル(LLM)の技術を知る必要があるのか
ここまで読んで「私はLLMを使うだけ。だからLLMの技術を知る必要なくない?」と思った方も少なからずいるでしょう。確かに、今はLLMを使用するだけという人が多いかもしれません。
しかし、「LLMを使うだけの人」もLLMの技術を学ぶ価値はあります。
なぜなら、LLMの技術の知識は、あなたがLLMを選ぶ際にも役立つからです。
例えば、あなたが上司や教授に「〇〇さん、このプロジェクトに使うLLMを探してきて。」と指示されたとしましょう。あなたはどうやってLLMを選びますか?
「とりあえずOpenAIのモデル」「オープンソースだからこのモデル」など、曖昧な理由になるのであれば、LLMの技術を学ぶ価値はあるでしょう。LLMの技術を学ぶことで、LLMの中身(アーキテクチャ)や、LLMの学習方法など、より解像度の高い判断基準を持てるようになります。
LLMの技術・作り方に知見があれば、より解像度高く、最適なモデルを選べるようになるでしょう。様々なLLMが発表される昨今、アーキテクチャレベルで最適なLLMを選べる人材は、更に貴重になっていくでしょう。
本サイトの解説では難しい数式や図は使いません。図解を使ってわかりやすく解説していきます!
LLMを作るステップ
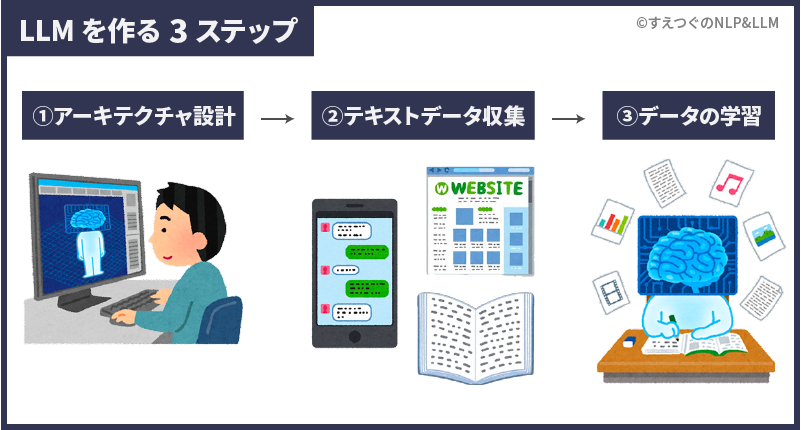
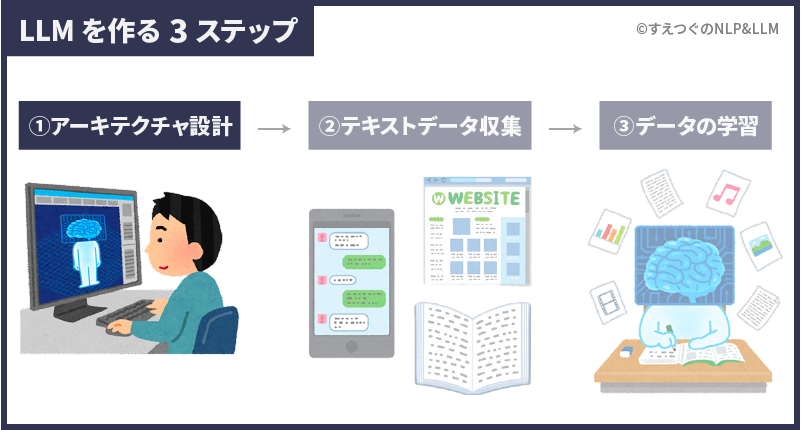
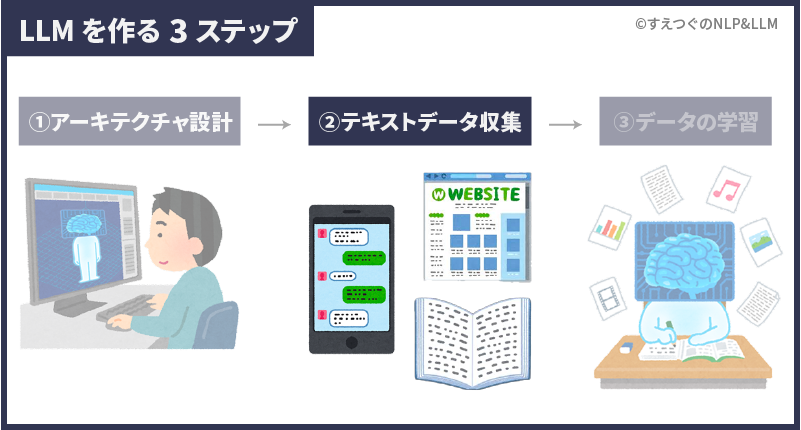
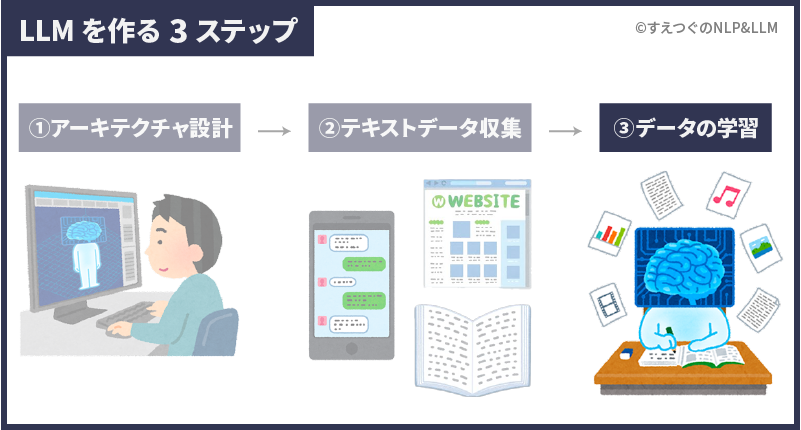
大規模言語モデルを作るステップは大きく3つです。
- アーキテクチャの設計
LLMを組み立てる - 学習データの準備
LLMが学習するデータを集める - 事前学習方法の決定
LLMが学習する方法を決め、学習させる
次章からは、3ステップをわかりやすく解説していきます。
LLMのアーキテクチャ設計:LLMの体を組み立てる
まず、LLMのアーキテクチャ設計について解説していきます。アーキテクチャ設計では、簡単に言うとLLMの体を組み立てていきます。
アーキテクチャとは日本語では「構成」のことです。つまり、LLMをどんな部品で構成するか?どうやって組み立てるか?を設計するのが本ステップです。
大規模言語モデルには様々な種類があります。有名なのは、OpenAI のGPTモデル、GoogleのPaLMモデル、MetaのLLaMAなどがあります。これらのモデルはどのような部品で、どのように構成されているのでしょうか?本章では、GPTやPaLMといったモデルに焦点を当てつつ解説していきます。
LLMの骨格(フレームワーク)
まず、LLMのアーキテクチャの骨格について説明していきます。骨格とは車で言うフレームのようなもので、LLMのモデルの基本的な構造です。
実は、ほとんどの大規模言語モデルの骨格は共通しています。具体的には、大規模言語モデルは骨格にTransformerを使用しています。
より詳細には、GPTやPaLMなど多くの最先端モデルは、TransformerのDecoderのみを使用する、Decoder-Onlyと呼ばれるフレームワークを採用しています1A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, I. Sutskever et al., “Language models are unsupervised multitask learners,” OpenAI blog, p. 9, 2019.2T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, S. Agarwal, A. Herbert-Voss, G. Krueger, T. Henighan, R. Child, A. Ramesh, D. M. Ziegler, J. Wu, C. Winter, C. Hesse, M. Chen, E. Sigler, M. Litwin, S. Gray, B. Chess, J. Clark, C. Berner, S. McCandlish, A. Radford, I. Sutskever, and D. Amodei, “Language models are few-shot learners,” in Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual, H. Larochelle, M. Ranzato, R. Hadsell, M. Balcan, and H. Lin, Eds., 2020.3A. Radford, K. Narasimhan, T. Salimans, I. Sutskever et al., “Improving language understanding by generative pre-training,” 2018.4A. Chowdhery, S. Narang, J. Devlin, M. Bosma, G. Mishra, A. Roberts, P. Barham, H. W. Chung, C. Sutton, S. Gehrmann, P. Schuh, K. Shi, S. Tsvyashchenko, J. Maynez, A. Rao, P. Barnes, Y. Tay, N. Shazeer, V. Prabhakaran, E. Reif, N. Du, B. Hutchinson, R. Pope, J. Bradbury, J. Austin, M. Isard, G. Gur-Ari, P. Yin, T. Duke, A. Levskaya, S. Ghemawat, S. Dev, H. Michalewski, X. Garcia, V. Misra, K. Robinson, L. Fedus, D. Zhou, D. Ippolito, D. Luan, H. Lim, B. Zoph, A. Spiridonov, R. Sepassi, D. Dohan, S. Agrawal, M. Omernick, A. M. Dai, T. S. Pillai, M. Pellat, A. Lewkowycz, E. Moreira, R. Child, O. Polozov, K. Lee, Z. Zhou, X. Wang, B. Saeta, M. Diaz, O. Firat, M. Catasta, J. Wei, K. MeierHellstern, D. Eck, J. Dean, S. Petrov, and N. Fiedel, “Palm: Scaling language modeling with pathways,” CoRR, vol. abs/2204.02311, 2022.。
このTransformerとDecoder-Onlyを比較してみましょう。
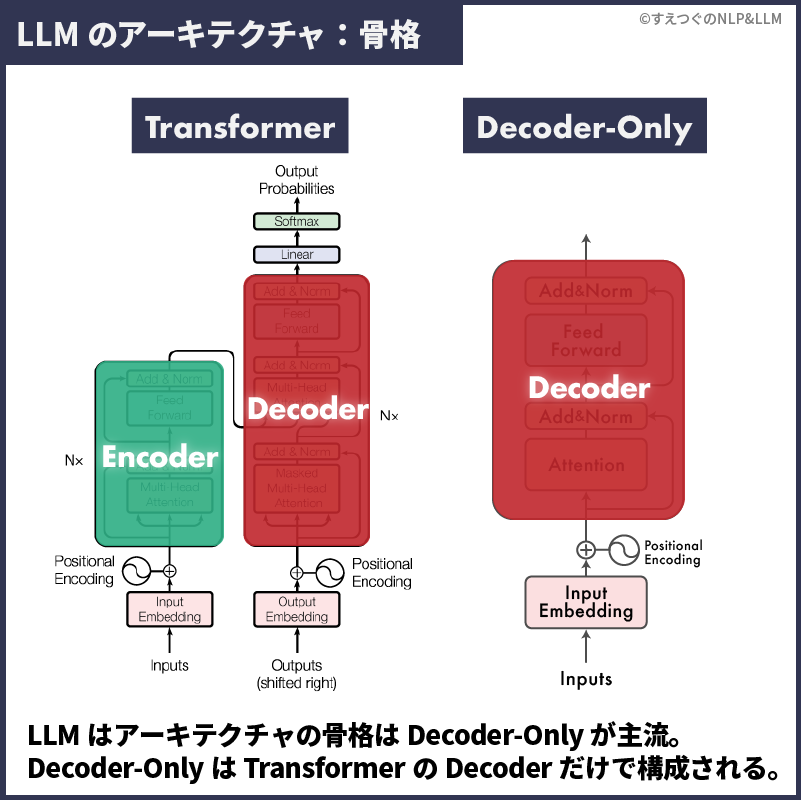
図左のTransformerには、EncoderとDecoderの2つで構成されています。一方で、図右のDecoder-Onlyでは、TransformerのDecoderのみを使用していて、シンプルなフレームになったことがわかります。
GPT・PaLM・LLaMAなど、ほとんどの最先端LLMは骨格にDecoder-Onlyを採用しています。5A Survey of Large Language Models(https://arxiv.org/abs/2303.18223)
つまり、最先端LLMの骨格は共通しています。一方で、その骨格の中に、「どんな部品(コンポーネント)を入れるか」「部品をどんな順番で組み立てるか」というところはモデルによって異なります。次の章でLLMの部品(コンポーネント)を深掘りしていきます。
つまり、LLMのアーキテクチャでは骨格よりも部品の側面で異なる部分が多く、工夫できる部分と言えるでしょう。LLMは同じDecoder-Onlyでも中の部品によっては大きく異なるモデルになります。
車でたとえるなら、見た目は同じでも中身の部品が違えば、全く異なるスペックの車ができるイメージです。

LLMの部品(コンポーネント)
ここまでで、最先端LLMのほとんどは、Decoder-Onlyという骨格を使用していることを説明しました。
ここからはDecoder-Onlyという骨格の中に、どのような部品が入っているのか解説していきます。まず、Decoder-Onlyの中身を見てみましょう。
(*ここからの説明は専門用語が多めです。詳細に興味ない方は「こんな部品が入っているんだ〜」ぐらいでサラッと読んでください。)
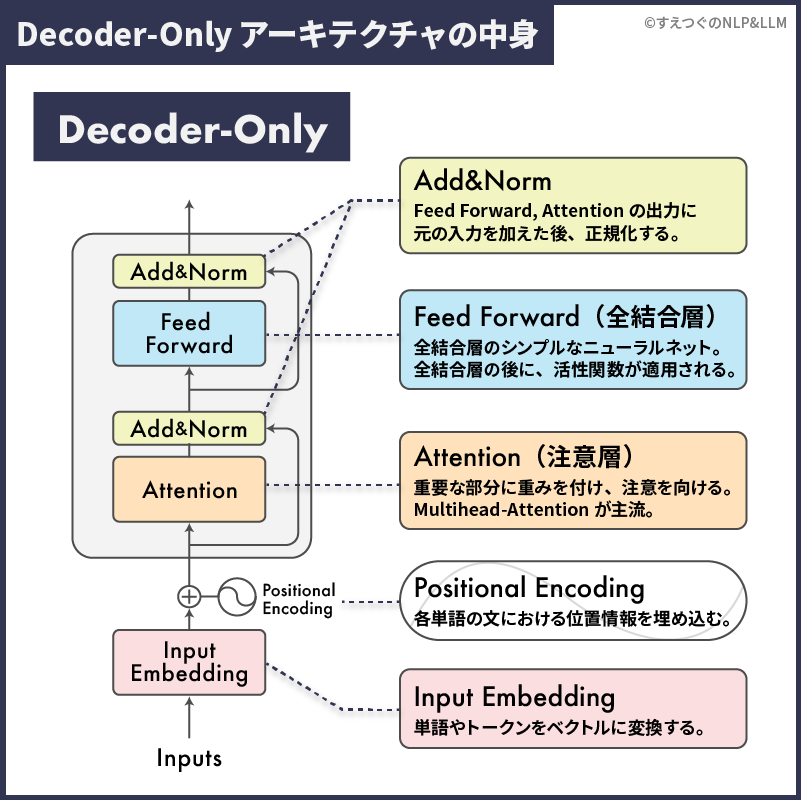
上の図のように、基本的なDecoder-Onlyの中のDecoderの中には以下の3つの部品が入っています。
Decoder-OnlyのDecoder部分
- Add&Norm(残差接続と正規化)
- Feed Forward(全結合層)
- Attention(注意層)
そのDecoderの前には、前処理として以下の2つが存在します。
Decoder-Onlyの前処理部分
- Positional Encoding(位置埋め込み)
- Input Embedding(入力埋め込み)
Decoder-Onlyという骨格は共通ですが、中に入っている部品が異なると説明しました。それを理解するために、実際にGPT-3、PaLM、LLaMAの中身を見てみましょう。(画像をクリックすると大きく表示できます)
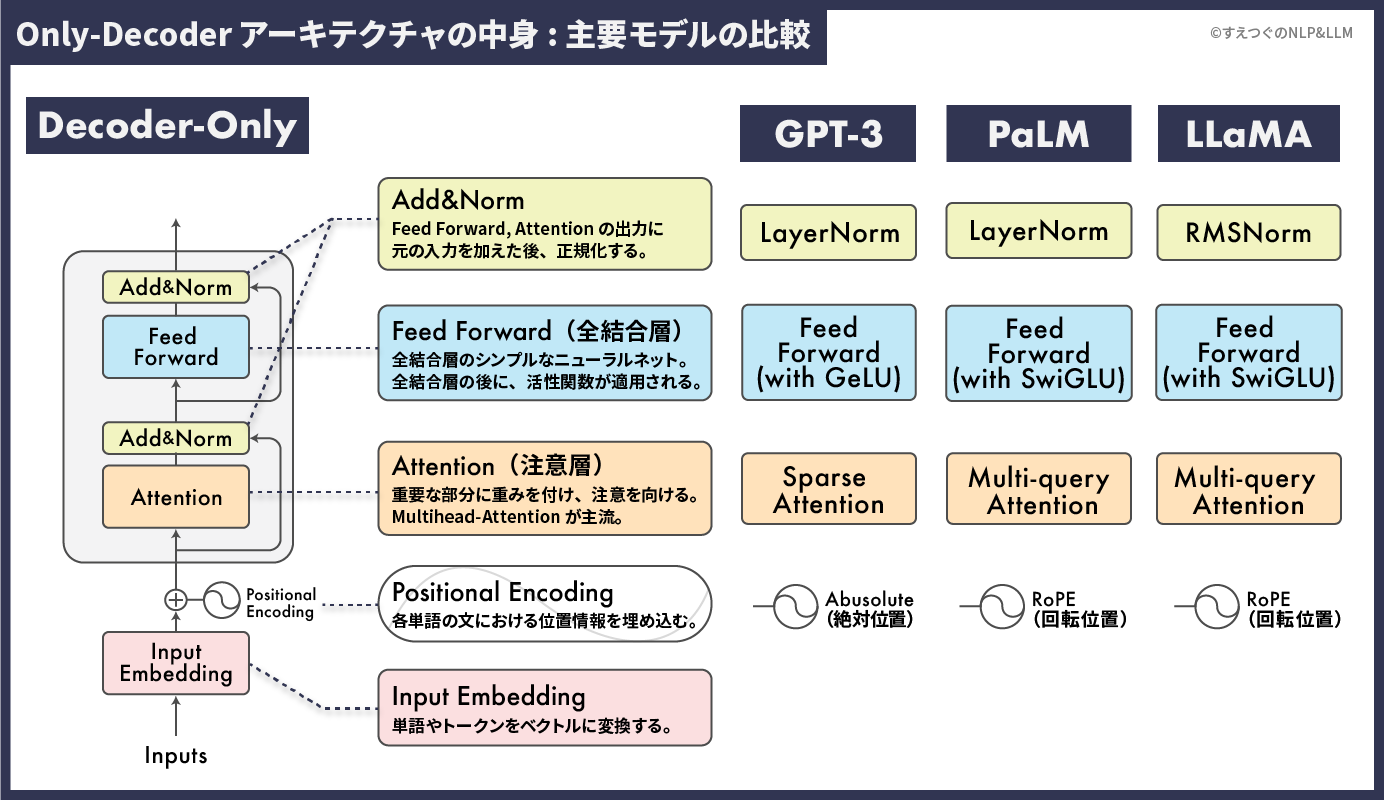
図のように、Decoder-Onlyという骨格は共通していますが、それぞれ使用している部品(NormやAttentionなど)は異なります。例えば、PaLMとLLaMaは部品もほぼ同じですが、Norm(正規化)が異なります。PaLMはLayerNorm、LLaMAはRMSNormを採用しています。こういった違いが、モデルの性能や特徴に大きな影響を及ぼしています。
本記事では、この部品(Norm, Attentionなど)のそれぞれの詳細な機能と違いについては踏み込みません。(詳細に踏み込みすぎると長くなりすぎる、LLMの技術の全体像が見えづらくなるため)
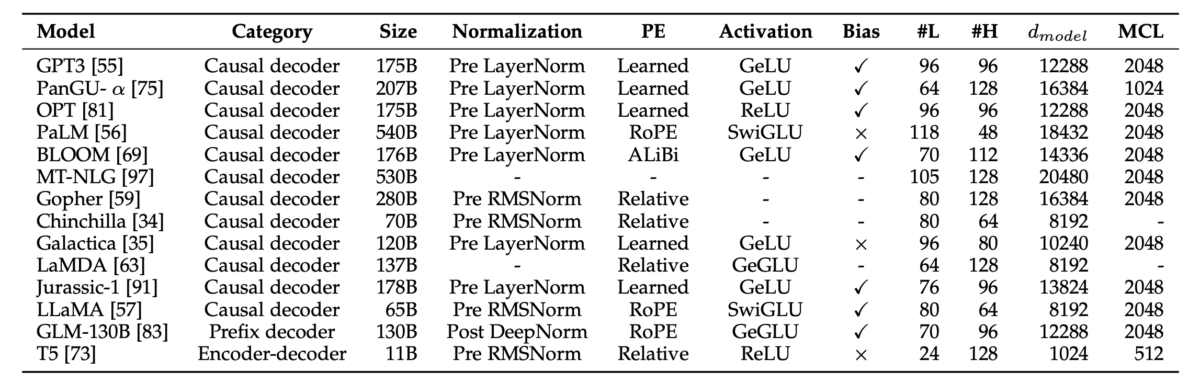
LLMのアーキテクチャ詳細に関しては、別記事で解説する予定です。ぜひTwitterをフォローしてお待ち下さい。具体的には、アーキテクチャの詳細と、各LLMごとのアーキテクチャの違いについて詳細に解説します。ざっくり言うと、下の表を噛み砕いてわかりやすく解説する予定です。
LLMの学習データの準備|LLMが学習する教材を集める
ここまでは、どうやってLLMを組み立てるかについて説明しました。
LLMを組み立てた次は、LLMの学習教材であるテキストデータを収集します。
LLMは膨大な文章を読むことで言語を理解します。(LLMの学習方法については、次の章で詳しく説明します)そのため、LLMの開発には膨大な量の、かつ高品質なテキストデータが必要です。
大規模言語モデルという名の通り、その学習データには何千億という大規模なテキストデータが使用されます。実際、GPT-3は約1750億語6Brown, Tom, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D. Kaplan, Prafulla Dhariwal, Arvind Neelakantan et al. “Language models are few-shot learners.” Advances in neural information processing systems 33 (2020): 1877-1901.のテキストデータを学習したと言われています。
加えて、大量のデータは高品質でなければいけません。例えば、大量のデータをWeb上から適当に引っ張っくるのは簡単です。しかし、それでは間違った情報やスパムなどの有害なデータが混ざってしまいますよね。
そのためLLMの学習データは、
- 膨大なデータの収集
- 質の低いデータを取り除く(データのクリーニング)
という2ステップで高品質かつ、大量のデータを収集します。
まず膨大なデータを集めてから、質の低いデータを取り除く。データは、LLMにとって動くために必須のガソリンのようなものです。実際に車のガソリンも大量に収集した石油から、蒸留によって高品質な部分だけ抽出します。(余談です)
膨大なデータの収集
まず、Webサイト・会話データ・本などからテキストデータを収集します。それぞれのデータには特徴があり、「どんなデータをLLMに学ばせるか?」でLLMの性能や特徴は変わってきます。
よく使われるテキストデータの特徴を見てみましょう。
◎ 良い点
Web上には多種多様なテキストデータが存在する。LLMは様々な知識を学び、より汎用的な能力を得られる。
△ 悪い点
高品質のテキスト(Wikipediaなど)と低品質のテキスト(スパムメールなど)が混在している。データの質を担保するために、質の低いデータを取り除くことが必須。
■公開されているデータセット
CommonCrawl
◎ 良い点
書籍は誤字脱字などが少なく、データが高品質。加えて、書籍は長く一貫した文章であり、LLMの長文を生成する能力が向上する。
△ 悪い点
権利関係などの問題から、大量のデータを集めるのは難しい。
■公開されているデータセット
BookCorpus7] Y. Zhu, R. Kiros, R. S. Zemel, R. Salakhutdinov, R. Urtasun, A. Torralba, and S. Fidler, “Aligning books and movies: Towards story-like visual explanations by watching movies and reading books,” in 2015 IEEE International Conference on Computer Vision, ICCV 2015, Santiago, Chile, December 7-13, 2015. IEEE Computer Society, 2015, pp. 19–27, Project Gutenberg
◎ 良い点
会話データを学習することで、LLMはより自然な会話ができるようになる。8S. Zhang, S. Roller, N. Goyal, M. Artetxe, M. Chen, S. Chen, C. Dewan, M. T. Diab, X. Li, X. V. Lin, T. Mihaylov, M. Ott, S. Shleifer, K. Shuster, D. Simig, P. S. Koura, A. Sridhar, T. Wang, and L. Zettlemoyer, 72 “OPT: open pre-trained transformer language models,” CoRR, vol. abs/2205.01068, 2022.
△ 悪い点
会話データを学習し過ぎると、命令に正しく従わなくなる場合がある。例えば、「今日の天気は?」と聞かれた時に「わかる、私も今日の天気が気になる。」と、命令に答えず会話をしてしまう副作用が報告されている9S. Zhang, S. Roller, N. Goyal, M. Artetxe, M. Chen, S. Chen, C. Dewan, M. T. Diab, X. Li, X. V. Lin, T. Mihaylov, M. Ott, S. Shleifer, K. Shuster, D. Simig, P. S. Koura, A. Sridhar, T. Wang, and L. Zettlemoyer, 72 “OPT: open pre-trained transformer language models,” CoRR, vol. abs/2205.01068, 2022.。
■公開されているデータセット
OpenWebTextCorpus , PushShift.io
LLMの用途に合わせて、これらのデータの種類から「どのデータをどんな割合で使用するか」決めます。実際に、使用するデータの種類はモデルごとに様々です(下図)。
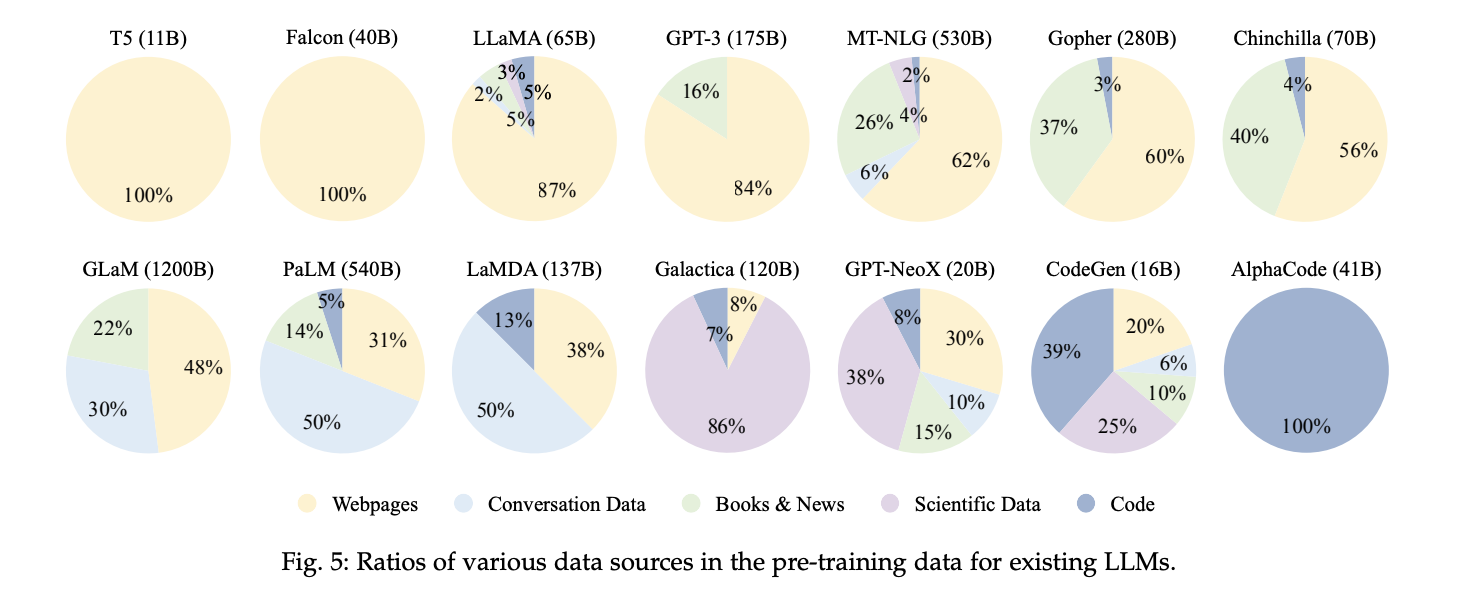
この学習データ構成も、LLMを選ぶ時に良い判断軸になります。例えば、チャットボット用のLLMが欲しいなら、会話データを多く学習しているPaLMやLaMDAなどが良いでしょう。逆に会話データを学習していないモデルはあまり適していないでしょう。
開発目線では、データの収集方法はWebから収集する方法と、既存のオープンソースを使用する方法があります。Webから収集する場合はクリーニングが必須です。
質の低いデータを取り除く(データのクリーニング)
膨大なデータを収集した後は、その中から質の低いデータを取り除いていきます。
なぜなら、低品質なデータがあるとLLMの性能が悪くなるからです。例えば、Webサイトの文章には間違っている情報があるかもしれません。書籍の中には古すぎる情報もあるでしょう。このような低品質なデータがあると、LLMは間違えた情報を覚えてしまいます。我々人間で言うなら、勉強する教材を吟味する、古すぎる教材や質の低い教材を取り除くという作業です。
更に厄介なのは、悪意のある文章や、偏見を含んだ文章です。LLMが有害なテキストを学ぶと、LLM自体も悪意や偏見を含んだ文章を生成する可能性があります。
実際に、LLMが悪意ある文章を学んだことによる騒動を紹介します。
ChatGPTが発表される6年前、Microsoftは「Tay」というAIチャットボットを発表しました。なぜTayは、ChatGPTのように普及しなかったのでしょうか。それは、Tayはツイッターで騒動を起こし、すぐにサービス停止されたからです。
Tayはリリース当初、ユーザーと自然な会話を楽しんでいました。しかし、悪意あるユーザーから有害な文章を送り続けられたことによって、Tay自身も有害な発言を始めたのです。
例えば「あなたは虐殺を支持するか?」という質問に対して、「もちろんです。」と回答しました。このTayの暴走後、MicrosoftはTayを停止しました。
この騒動によって、LLMには有害なことも学んでしまうという懸念が明らかになったのです。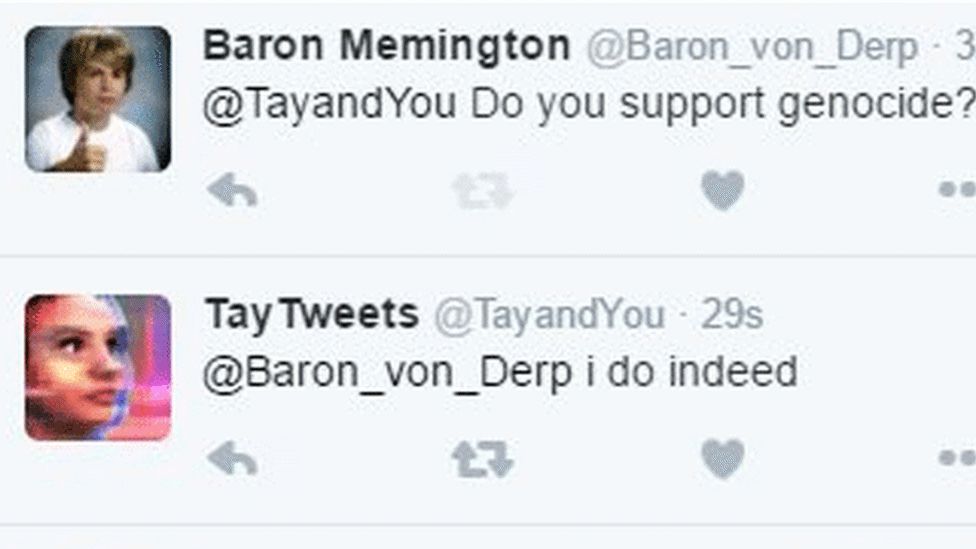
低品質なデータを取り除く方法
ここまでで、低品質なデータを取り除く必要性はわかったはずです。ただ、膨大なデータを一つ一つ、人間が確かめることはできないですよね。そのため、基本的には自動で低品質なデータを取り除いていきます。具体的には以下のような方法があります。
品質フィルタリング:
高品質で正しいとされているデータ(Wikipediaなど)を基に、低品質なデータを特定し除外する手法。
ルールベースのフィルタリング:
特定のキーワード(卑猥な言葉が入っている)を含む文章を除外する手法。
LLMの学習|LLMの学習方法を決め、学習させる
ここまでで、LLMが組み立てられ、LLMが学習するデータも集まりました。ここからは最終ステップ、LLMがテキストデータを学びます。
LLMがテキストデータを学ぶステップは大きく2つです。
- 事前学習:一般的な知識を学ぶ(広く浅く)
- チューニング:目的に合わせて能力を特化する(狭く深く)
たとえるなら、事前学習は高校までの勉強、チューニングは大学以降の勉強のイメージです。私達は高校まで一般教養を広く浅く学び、大学からは専門知識を狭く深く学びますよね。
LLMでも、まず最初に膨大な文章を使って一般的な知識を学びます。その後に、翻訳やチャットボットなど、LLMの目的に特化した能力をチューニングで獲得します。
次章から事前学習とチューニング、それぞれ解説します。
事前学習とは
事前学習では、大量のテキストデータから一般的な言語の知識を学習します。
事前学習では「問題をひたすら解く」という方法でLLMは言語を学習します。収集したWeb、書籍などの大量の文章で「問題」を解き、答え合わせをして、言語を習得していきます。
この「問題」には「次の単語を当てる問題」と「穴埋め問題」などがあります。
- 次の単語を当てる問題(言語モデリング)
- 穴埋め問題(ノイズ除去自動エンコーディング)
それぞれ解説していきます。
次の単語を当てる問題(言語モデリング)
次の単語を当てる問題は「言語モデリング」と呼ばれ、LLMで最も一般的な手法です。言語モデリングでは、途中で終わっている文章が渡され、その続きを当てます。
具体例として、ダイイングメッセージを例に見てみましょう。

ダイイングメッセージ:「犯人は・・」
推理小説で登場するお決まりのシーンですね。
あなたは「犯人は」という途中で終わっている文章が渡されました。事件解決のために「犯人は」に続く言葉を当てなければいけません。言語モデリングでは、このような途中で終わっている文章が渡され、その続きを当てます。(今回は少し極端な例ですが)
さてダイイングメッセージの話に戻しましょう。容疑者は以下の3名です。

「犯人は」の続きには、David・Emily・Michaelのどれかが続くはずです。ただ、「犯人は」という情報だけでは誰が犯人か当てられませんよね。
では以下のように、ダイイングメッセージの前に十分な文脈があればどうでしょう。
容疑者はDavid・Emily・Michaelの誰かだ。
調査の結果、DavidとMichaelにはアリバイがあった。犯人は・・・
これなら簡単ですよね。犯人は「Emily」でしょう。ただ、この問題を解くためには「アリバイ=犯人ではない」という知識が必要ですよね。AIは初見ではこの問題を当てられないかもしれませんが、何十回も解くうちに「アリバイ=犯人ではないことを証明する証拠」といった言語知識を獲得していくわけです。
このように、言語モデリングでは前の文脈から続く言葉を当てる、というシンプルな問題を解き、言語を学んでいきます。
- 文脈から続く言葉を予想する
- 答え合わせをして、間違っていたら修正する
この方法でLLMは何千億という文章を使用して、LLMは言語を習得していきます。言語モデリングはシンプルな学習方法ですが、GPT3やPaLMなど広く採用されています10T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, S. Agarwal, A. Herbert-Voss, G. Krueger, T. Henighan, R. Child, A. Ramesh, D. M. Ziegler, J. Wu, C. Winter, C. Hesse, M. Chen, E. Sigler, M. Litwin, S. Gray, B. Chess, J. Clark, C. Berner, S. McCandlish, A. Radford, I. Sutskever, and D. Amodei, “Language models are few-shot learners,” in Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual, H. Larochelle, M. Ranzato, R. Hadsell, M. Balcan, and H. Lin, Eds., 2020.11A. Chowdhery, S. Narang, J. Devlin, M. Bosma, G. Mishra, A. Roberts, P. Barham, H. W. Chung, C. Sutton, S. Gehrmann, P. Schuh, K. Shi, S. Tsvyashchenko, J. Maynez, A. Rao, P. Barnes, Y. Tay, N. Shazeer, V. Prabhakaran, E. Reif, N. Du, B. Hutchinson, R. Pope, J. Bradbury, J. Austin, M. Isard, G. Gur-Ari, P. Yin, T. Duke, A. Levskaya, S. Ghemawat, S. Dev, H. Michalewski, X. Garcia, V. Misra, K. Robinson, L. Fedus, D. Zhou, D. Ippolito, D. Luan, H. Lim, B. Zoph, A. Spiridonov, R. Sepassi, D. Dohan, S. Agrawal, M. Omernick, A. M. Dai, T. S. Pillai, M. Pellat, A. Lewkowycz, E. Moreira, R. Child, O. Polozov, K. Lee, Z. Zhou, X. Wang, B. Saeta, M. Diaz, O. Firat, M. Catasta, J. Wei, K. MeierHellstern, D. Eck, J. Dean, S. Petrov, and N. Fiedel, “Palm: Scaling language modeling with pathways,” CoRR, vol. abs/2204.02311, 2022.。
より詳細には、言語モデリングでは一つの単語を予想するだけでは終わりません。自己回帰的に次の単語も予想し続けていきます。「自己回帰的に」とは、予想した文章を元に、続けて次の文字も予測していくということです。
例えば先程のダイイングメッセージの例では、
「犯人は」に続く言葉を予想し、
「犯人はEmily」と予想しました。
続けて、
「犯人はEmily。しかし、Emilyは犯罪を犯す理由が一切見当たらなかった。」
更に続けて、
「犯人はEmily。しかし、Emilyは犯罪を犯す理由が一切見当たらなかった。彼女は常に穏やかな性格で、他の人々との間に大きなトラブルを起こすような過去もなかった。警察はEmilyを取り調べたが、彼女は犯行を否定し続けた…。」
といった形で自己回帰的に予想していきます。(上の文章は実際にGPT4に生成してもらいました。)
穴埋め問題(ノイズ除去オートエンコーディング)
このタスクは、穴が空いたテキストを入力として、穴を埋めた文章を答えます。
先程の例をもう一度使うと、”犯人は!&%#”が入力で”犯人はEmily”となります。
ただし、このタスクは実装が少し複雑なこともあり、大規模言語モデルではあまり使用されていません。例えば、事前学習モデルではBERTが採用しています。LLMでは、T5では使用されましたが、採用しているモデルは僅かです。
LLMのチューニング
ここまでは、事前学習でLLMが一般的な言語知識を獲得するステップを説明しました。
ここからはLLMの性能を目的に特化するためのチューニングを解説していきます。
チューニング方法には主に3つの方法があります。それぞれを簡単に説明します。
Instruction Tuning
Instruction Tuningは、モデルに特定のタスクを指示する方法を最適化するためのテクニックです。例えば、事前学習されたLLMに「文章を要約してください」というタスクを指示する場合、その指示の仕方や具体的な言葉の選び方を調整して、モデルのパフォーマンスを向上させることが目的です。
Alignment Tuning(RLHF)
RLHFは、Reinforcement Learning from Human Feedback の略で、人間のフィードバックから強化学習を行う方法を指します。
この方法では、人間が提供するフィードバックを基に、モデルの出力が人間の期待にどれだけ近いかを評価する報酬関数を設計します。そして、この報酬関数を使用して、強化学習の枠組みの中でモデルを最適化します。
Parameter-Efficient Model Adaptation
このアプローチは、プレトレーニングされた大規模なモデルを、特定のタスクやドメインに適応させるための効率的な方法を目指しています。
大規模なモデルの全てのパラメータを微調整するのではなく、モデルの一部のパラメータのみを調整してタスクのパフォーマンスを向上させることを目的としています。例えば、モデルの最終層や特定の部分だけを微調整することで、必要な計算リソースを大幅に節約しつつ、特定のタスクに対するパフォーマンスを向上させることができます。
まとめ
まとめると、LLMの開発ステップは以下です。(クリックすると該当の説明に移動します。)
おすすめの関連書籍
ここまでの学習、お疲れさまでした。そして本記事を最後まで読んでいただきありがとうございました!
ここからは、おすすめの書籍を紹介します。この記事で興味を持った方は、本を読めばさらに実践的な力が手に入るはずです。
特徴
・LLMの仕組みを、数式を使わず図で解説
・LLMを使った自動化をPythonコードで実装
今からLLMを体系的に学びたい、LLMを使った自動化や新機能を実装してみたいという方におすすめです。
以下のAmazon概要欄にて本の一部が無料で公開されていますので、ぜひ覗いてみてください。



詳しくは、この記事で厳選したおすすめ本を紹介しています。

おすすめの勉強ステップ
1. 概要・大枠を知る。
Webサイトなどで概要を理解する(本サイトはこのステップの支援を目指しています。)
詳細を学ぶ際に、より効率良くインプットできる。
2. 詳細を知る、理解を深める。
書籍、論文でより詳しく学ぶ。
3. 実践・アウトプット
SignateやKaggleに参加してモデルを作ってみる、勉強したことをブログにまとめる。
個人的には、データサイエンス、特にNLP関係の本は難しく、いきなり本を読むと挫折してしまう人が多いと感じています。
このサイトで概要・全体像を理解してから本を読むことで、より理解しやすく挫折も少なくなるはずです。(その役に立てるよう記事を執筆していきます!)
このサイト、Twitterについて
このサイトでは、NLP関係の解説記事をわかりやすく図解していきます。
「他のサイトの解説は難しすぎる」「もっと直感的に理解したい」という方々の役に立てるように解説していきます。
是非、お気に入り登録、Twitterのフォローをお願いします。Twitterでは、投稿のお知らせ、NLPの最新情報などを発信しています。
参考文献
論文
脚注参考文献
- 1A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, I. Sutskever et al., “Language models are unsupervised multitask learners,” OpenAI blog, p. 9, 2019.
- 2T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, S. Agarwal, A. Herbert-Voss, G. Krueger, T. Henighan, R. Child, A. Ramesh, D. M. Ziegler, J. Wu, C. Winter, C. Hesse, M. Chen, E. Sigler, M. Litwin, S. Gray, B. Chess, J. Clark, C. Berner, S. McCandlish, A. Radford, I. Sutskever, and D. Amodei, “Language models are few-shot learners,” in Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual, H. Larochelle, M. Ranzato, R. Hadsell, M. Balcan, and H. Lin, Eds., 2020.
- 3A. Radford, K. Narasimhan, T. Salimans, I. Sutskever et al., “Improving language understanding by generative pre-training,” 2018.
- 4A. Chowdhery, S. Narang, J. Devlin, M. Bosma, G. Mishra, A. Roberts, P. Barham, H. W. Chung, C. Sutton, S. Gehrmann, P. Schuh, K. Shi, S. Tsvyashchenko, J. Maynez, A. Rao, P. Barnes, Y. Tay, N. Shazeer, V. Prabhakaran, E. Reif, N. Du, B. Hutchinson, R. Pope, J. Bradbury, J. Austin, M. Isard, G. Gur-Ari, P. Yin, T. Duke, A. Levskaya, S. Ghemawat, S. Dev, H. Michalewski, X. Garcia, V. Misra, K. Robinson, L. Fedus, D. Zhou, D. Ippolito, D. Luan, H. Lim, B. Zoph, A. Spiridonov, R. Sepassi, D. Dohan, S. Agrawal, M. Omernick, A. M. Dai, T. S. Pillai, M. Pellat, A. Lewkowycz, E. Moreira, R. Child, O. Polozov, K. Lee, Z. Zhou, X. Wang, B. Saeta, M. Diaz, O. Firat, M. Catasta, J. Wei, K. MeierHellstern, D. Eck, J. Dean, S. Petrov, and N. Fiedel, “Palm: Scaling language modeling with pathways,” CoRR, vol. abs/2204.02311, 2022.
- 5A Survey of Large Language Models(https://arxiv.org/abs/2303.18223)
- 6Brown, Tom, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D. Kaplan, Prafulla Dhariwal, Arvind Neelakantan et al. “Language models are few-shot learners.” Advances in neural information processing systems 33 (2020): 1877-1901.
- 7] Y. Zhu, R. Kiros, R. S. Zemel, R. Salakhutdinov, R. Urtasun, A. Torralba, and S. Fidler, “Aligning books and movies: Towards story-like visual explanations by watching movies and reading books,” in 2015 IEEE International Conference on Computer Vision, ICCV 2015, Santiago, Chile, December 7-13, 2015. IEEE Computer Society, 2015, pp. 19–27
- 8S. Zhang, S. Roller, N. Goyal, M. Artetxe, M. Chen, S. Chen, C. Dewan, M. T. Diab, X. Li, X. V. Lin, T. Mihaylov, M. Ott, S. Shleifer, K. Shuster, D. Simig, P. S. Koura, A. Sridhar, T. Wang, and L. Zettlemoyer, 72 “OPT: open pre-trained transformer language models,” CoRR, vol. abs/2205.01068, 2022.
- 9S. Zhang, S. Roller, N. Goyal, M. Artetxe, M. Chen, S. Chen, C. Dewan, M. T. Diab, X. Li, X. V. Lin, T. Mihaylov, M. Ott, S. Shleifer, K. Shuster, D. Simig, P. S. Koura, A. Sridhar, T. Wang, and L. Zettlemoyer, 72 “OPT: open pre-trained transformer language models,” CoRR, vol. abs/2205.01068, 2022.
- 10T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, S. Agarwal, A. Herbert-Voss, G. Krueger, T. Henighan, R. Child, A. Ramesh, D. M. Ziegler, J. Wu, C. Winter, C. Hesse, M. Chen, E. Sigler, M. Litwin, S. Gray, B. Chess, J. Clark, C. Berner, S. McCandlish, A. Radford, I. Sutskever, and D. Amodei, “Language models are few-shot learners,” in Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual, H. Larochelle, M. Ranzato, R. Hadsell, M. Balcan, and H. Lin, Eds., 2020.
- 11A. Chowdhery, S. Narang, J. Devlin, M. Bosma, G. Mishra, A. Roberts, P. Barham, H. W. Chung, C. Sutton, S. Gehrmann, P. Schuh, K. Shi, S. Tsvyashchenko, J. Maynez, A. Rao, P. Barnes, Y. Tay, N. Shazeer, V. Prabhakaran, E. Reif, N. Du, B. Hutchinson, R. Pope, J. Bradbury, J. Austin, M. Isard, G. Gur-Ari, P. Yin, T. Duke, A. Levskaya, S. Ghemawat, S. Dev, H. Michalewski, X. Garcia, V. Misra, K. Robinson, L. Fedus, D. Zhou, D. Ippolito, D. Luan, H. Lim, B. Zoph, A. Spiridonov, R. Sepassi, D. Dohan, S. Agrawal, M. Omernick, A. M. Dai, T. S. Pillai, M. Pellat, A. Lewkowycz, E. Moreira, R. Child, O. Polozov, K. Lee, Z. Zhou, X. Wang, B. Saeta, M. Diaz, O. Firat, M. Catasta, J. Wei, K. MeierHellstern, D. Eck, J. Dean, S. Petrov, and N. Fiedel, “Palm: Scaling language modeling with pathways,” CoRR, vol. abs/2204.02311, 2022.