こんにちは!自然言語処理(NLP)・大規模言語モデル(LLM)の解説記事や書籍を書いている、
すえつぐです!
お知らせ:著書 『誰でもわかる大規模言語モデル入門』 を日経BPより出版しました。
突然ですが、BERT、GPT-3、PaLMを使ったことはありますか?Transformerはこれらの最先端のモデルに使用されている、現代のNLPモデルには欠かせないモデルです。おそらくBERTやGPT-3でTransformerを知った、このページに来たという人も多いのではないでしょうか。機械学習、特にNLPの勉強をしている方々は、Transformerの概要は知っておいた方が良いと思います。
ただ多くのサイトは、いきなり細かい仕組みの解説をする中級者以上向けの記事が多いですよね。
そこで、このページでは、Transformerの入門〜中級までの解説をしていきます!まず入門として、「Transformerの使い道」「Transformerの何が凄いのか?」を先に解説します。その上で「Transformerの仕組み」についてもわかりやすく解説していきます。
図解シリーズについて本サイトの「図解シリーズ」ではオリジナルの図解を使って、わかりやすく、誰にでもわかるように解説していきます。そのため他のサイトで使われているような難しい図や数式は一切使いません。「わかりやすさに全振りした、楽して理解できる記事」をテーマにしています。数式や詳細が知りたい方は原論文を参照してください。たまに「*」をつけて補足しますが、基本的に読み飛ばして大丈夫です。
Transformerの使い道は?現在使われているモデル
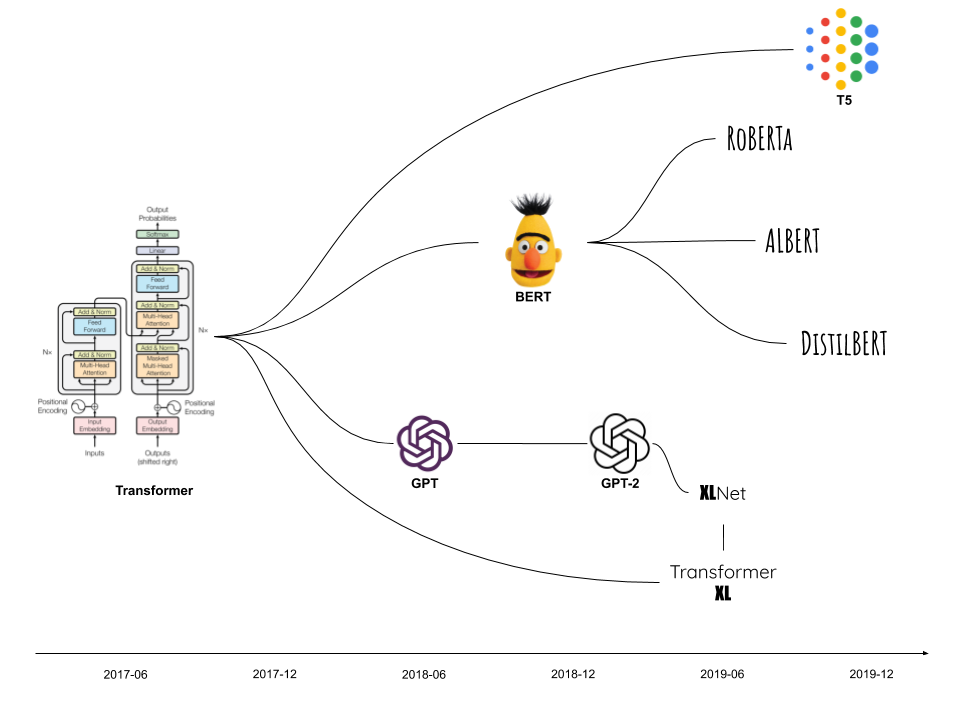
近年、機械学習、特にNLPのモデルでTransformerをベースにしたモデルが開発され続けています。有名どころでは、BERT、GPT、PaLMなどの大規模モデルがTransformerをベースにしています。加えて、そのBERTやGPTを更に発展させた、ROBERTAやGPT-3などが開発されています。近年のNLPモデルはTransformerをベースに進化し続けている、と言っていいでしょう。
Transformerベースの中でも、特に有名でビジネスにも使われているモデル、BERT、GPTシリーズの詳細を見てみましょう。

BERT(Google開発)
得意とすること
- テキストの分類、分析
- 長い文章の要約
実際のビジネスなどでの使用例
- フェイクニュースの特定、レビューの感情分析、スパムの除去
- 書籍、法律文書などの要約
- Google検索をより最適化
GPTシリーズ(OpenAI開発)
得意とすること
- 自然な文章の生成
- コードの自動生成
実際のビジネスなどでの使用例
- 自然な質疑応答
- コードの自動生成
- 記事やポッドキャストの執筆
BERTやGPT-3などのモデルは既に「人間と同レベルの理解力」を持っているとも言われており、ビジネスへの応用が進んでいます。
イメージとしては、Transformerは車の部品で言えば、「使い勝手の良いシンプルで高機能なエンジン」のようなものです。BERTやGPTはTransformerという強力なエンジンを積んだ車(モデル)なわけです。実際に、BERT、GPTだけでなく、数多くのモデルがTransformerを使用しています。
これは少し余談ですが、最近のNLPモデルはどんどん巨大になってきています。実際に、GPT-3(2020年発表)のパラメータは「1750億」、PaLM(2022年発表)のパラメータは「5400億」です。
このモデルの巨大化の流れに対して、軽量化を試みるモデルも生まれてきています。例えば、ALBERTはBERTの軽量化&性能向上を行ったモデルです。
これからは性能向上だけではなく、「どうやって軽量化するか」というテーマも重要になっていくでしょう。
なぜ最新モデルにTransformerが使われているのか?Transformerの凄さ
一言で言うと、Transformerは「処理が速い!精度も高い!しかも汎用性が高くて何にでも使える!」モデルです。
Transformerは従来モデルと比較して「高速化、高精度化、より汎用的」したことで世界に衝撃を与えました。(従来モデルについては後の仕組みの部分で詳しく説明します)
そして、その汎用性からTransformerはBERTやGPT、画像処理のViTなど、数多くの最先端モデルに使用されました。(もはや、頭が良くてスポーツもできて性格も良い、みたいなそんなイメージです。)
Transformerの長所を一つ一つ見ていくと以下のようになります。
- 高速化:処理が速い
並列化によって学習時間を大幅に短縮。 - 精度向上:精度が高い
英独翻訳タスクで、アンサンブルを含む従来モデルの最良結果を超える。*28.4BLEU、従来より2BLEU以上上回る - 汎用的で、大規模なモデルも構築可能:汎用性が高い
大規模な学習データを学習することが可能。後にBERT、GPTなどの大規模な学習データを使ったモデルに応用。
Transformerのイノベーション、「並列化」
Transformerの革新的な部分として「従来の逐次処理から並列処理を可能にしたこと」が挙げられます。それまでのモデルでは逐次処理、つまり単語を一つ一つ処理する必要がありました。
一方で、Transformerは並列処理、つまり複数の処理を同時に行うことを可能にしました。*厳密にはEncoder部分の並列化を実現
![]()
この並列化によって、より高速な処理を行うことを可能にしました。並列化によって、同時に複数のタスクを処理することで、一つ一つのタスクの処理時間を短縮できるようになりました。
加えて、並列処理が可能になったことで、GPUの恩恵を受けることができます。
データサイエンスのコードを書いたことがある方は「CPUよりもGPUの方が速い」ことを、なんとなく知っているのではないでしょうか。
GPUは並列処理ができ、GPUの数を増やすことで学習の高速化を可能にします。
Transformerの並列化ができる点は、GPUの並列化と非常に相性が良く、学習のさらなる高速化を実現しました。
GPUの並列処理に関しては、この動画がわかりやすいです。CPUとGPUの処理を比較した実験が行われています。
POINT「並列化」がTransformerで非常に重要なことがわかっていただけたと思います。ここからの仕組みに関する解説でも「並列化」を覚えておくと理解がしやすいと思います。
Transformerはどんな問題を解決したのか?従来モデルの問題点
ここまでは「Transformerの凄さ」を解説してきました。ここからは従来モデルとTransformerを比較して、Transformerが「なぜ凄いのか?」について解説していきます。
ここからは少し専門用語を出してより詳しく説明していきます。専門用語には補足か解説記事を載せるので参考にしていください。
今回のタスクここでは「日本語から英語へ翻訳する」というタスクを使って、従来モデルとTransformerの比較を行っていきます。*原論文は英語を独語に翻訳するタスクです。よりわかりやすくするために日→英翻訳にして解説します。
従来モデルの問題点
Transformer以前は、主にRNNとをベースとしたモデルが使用されていました。
しかし、RNNを使用した従来モデルには、二つの大きな問題点がありました。それが、「長期記憶が苦手」、「並列処理ができない」という問題です。
従来モデルの問題点① 長期記憶が苦手
一つ目は「長期記憶が苦手」なことです。つまり翻訳であれば、長い文章になればなるほど精度が落ちてしまいます。
例えば、長い文章の後半になると、従来モデルは最初に起こったことを忘れてしまいます。長文の後半部分を翻訳しようとすると「文章の主語がIだったのかHeだったのかを忘れてしまう」といった問題が起きていました。
これは従来モデルがRNNを採用していて、「RNNは文章を順番に処理していくため古い情報を忘れてしまう」ことから起きていました。
従来モデルの問題点② 並列処理ができない
二つ目が「並列処理ができない」ことです。これは1つ目の問題と同じことが原因で、「RNNは文章を順番に処理する」ため、一気に計算する並列計算ができませんでした。
並列化ができないと学習スピードが遅い、大規模な学習データを使用できないという大きなデメリットがありました。
二つの問題点をTransformerはどうやって改善したか?
鋭い方は既にお気づきかもしれませんが、両方の問題ともRNNが原因です。
RNNは文章の文脈を理解できるという強みがありました。一方で、「長期記憶が苦手」「並列処理ができない」という二つの大きな問題を抱えていました。
そこでTransforemer以前は、RNNを使いながらどうにかこの問題を解決しようとする試みが行われていました。
実際、「長期記憶が苦手」はLSTMなどのモデルで改善されました。しかし、LSTMは長期記憶を改善したものの並列化はできませんでした。加えてモデルが複雑になったため、処理がより遅くなってしまいました。
そんな中、「そもそもRNNを使わない」という、ちゃぶ台返しをしたのがTransformerです。そして、この二つの問題とも改善してしまったわけです。
![]()

従来モデル、RNNベースのEncoder-Decoderモデルとは
ここまで説明した「長期記憶ができない」と「並列化できない」という従来モデルのデメリットを踏まえて、従来モデルのRNNベースのEncoder-Decoderモデルの仕組みを詳しく見ていきましょう。
Encoder-Decoderモデルとは?
まず、「RNNのEncoder-Decoderモデル」を説明する前に、「Encoder-Decoderモデル」についてわかりやすく説明します。
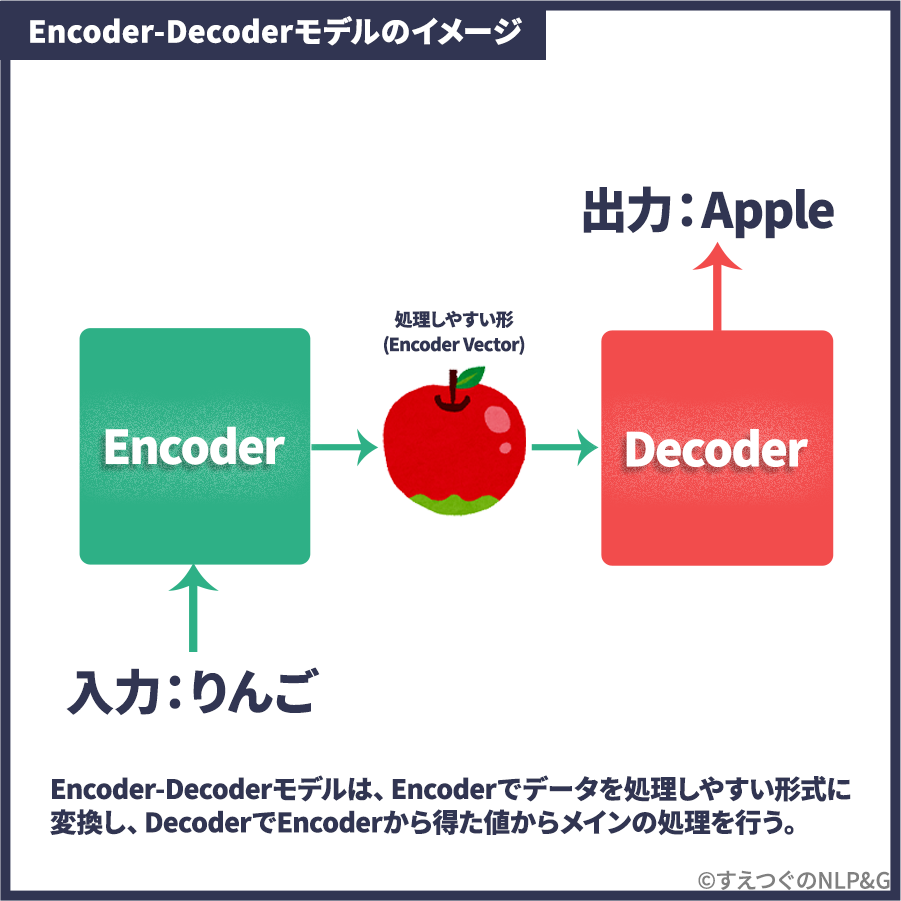
Encoder-Decoderモデルの特徴は、EncoderとDecoderという二つのブロックを作り、作業を分担することです。
Encoderでデータを処理しやすい形式に変換し、DecoderでEncoderから得た値からメインの処理を行います。下の画像のように、一度処理しやすい形にしてから、メインの処理をする、というシンプルな仕組みです。(図は翻訳タスクの例です。りんごという日本語を、Encoderで一度絵(Encoder-vector)にしてから、Appleという英語をDecoderで出力しています。)
RNNベースのEncoder-Decoderモデルとは?
RNNベースのEncoder-Decoderモデルは、下図のような仕組みになっています。

Transformerはどうやって従来モデルを改善したか?
ここまでで「長期記憶ができない」「並列化できない」という従来モデルのデメリットを紹介しました。ここからは、「Transformerはどうやって従来モデルを改善したか?」を図解していきます。
この答えは原論文を引用すると
Transformerは、Encoder-Decoderのアーキテクチャで最もよく使われるRNNをMulti-head Attentionに置き換えた、完全にAttentionに基づく最初のシーケンス変換モデル。
つまり、問題の原因になっていたRNNを取り除いて、Multi-head Attentionに置き換えたということです。イラストをもう一度見てみましょう。
![]()
ここまで読まれた方は、「Multi-head Attentionって何?」と思われてると思います。これについては後ほど詳しく説明します。
先に言ってしまうとMulti-head AttentionがTransformerの仕組みで最も重要な部分です。なぜなら、この仕組みによって従来モデルの「長期記憶ができない」「並列化できない」という二つの問題を解決したからです。
次の章でMulti-head Attentionを含めたTransformerの仕組みを説明していきます。
Transformerの仕組みを図を使って解説
ここからはTransformerの仕組みについても踏み込んで話していきます。そのため、少し難しく感じる部分も出てくるかもしれません。専門知識に関しては、補足か関連記事を載せておきます。
Transformerの全体像
Transformerの仕組みは以下のようになっています。この複雑で難しい図で挫折してしまった人も多いはずです。ここからはこの図を細かく分解し、わかりやすく解説していきます。
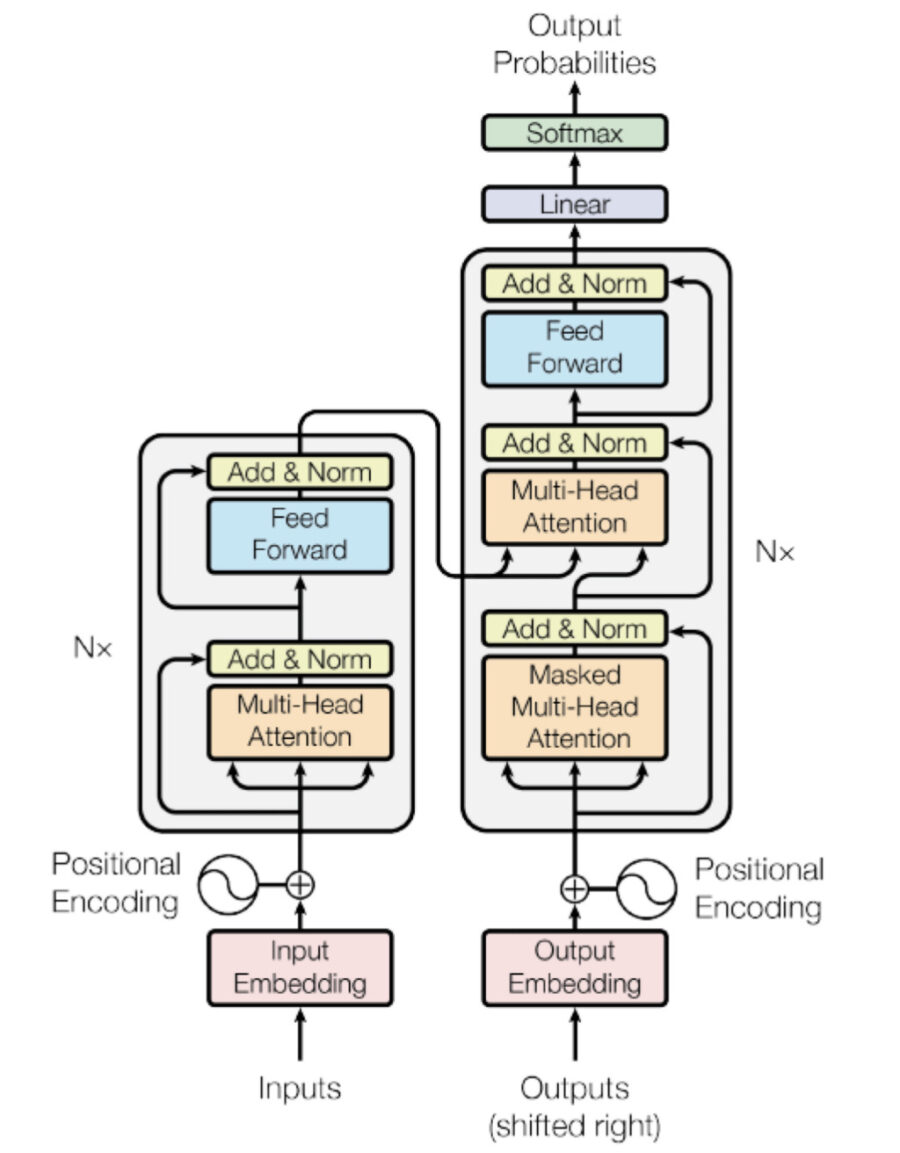
今はかなり難しく見えると思いますが、この図を一つずつ、わかりやすく図解していきます。
TransformerをEncoderとDecoderに分解
まずこの図はEncoderとDecoderに分けることができます。
![]()
EncoderとDecoderに分けると、大枠はほぼ従来のEncoder-Decoderモデルと同じことがわかります。実際、
- TransformerでもEncoderで入力(翻訳する文章)を処理しやすい値に変換
- Decoderでメインの処理を行う
という流れは一般的なEncoder-Decoderと同じです。異なるのは、従来はEncoderとDecoderの中にRNNが入っていたのに対して、TransformerにはRNNは入っていないことです。
つまり、モデルの大枠は従来モデルと変わらず、その中身が変わったということです。
その中身、「EncoderとDecoderの中身」について次の章で解説していきます。
*本記事では深く触れませんが、Transformerでは、EncoderとDecoderの処理の前に、前処理(EmbedingとPositional Encoding)が行われます。Positional EncodingはTransformer独自の新しい仕組みです。気になった方はこちらのサイトがわかりやすいと思います。また、Decoderの後にも線形層とSoftmaxを行い出力値に変換する処理が行われます。
TransformerのEncoderとDecoderの中身
ではEncoderとDecoderの中身を見ていきましょう。
![]()
従来モデルにはEncoderとDecoderにRNNが入っていましたが、Transformerの場合は、
- 「Multi-head Attentionを使ったブロック(Self-Attention, Masked Self-Attention)」
- 「Neural Networkのブロック(Feed Forward)」
で構成されています。
Multi-head Attentionの仕組み
Multi-head Attentionについて説明していきます。
![]()
イメージとしては、Multi-head AttentionはAttentionの進化版です。Multi-head AttentionはAttentionよりも複数箇所の重要な部分に注目することができます。これによって、Multi-head AttentionはAttentionよりも、より文脈を理解することができます。
まとめ
- Transformerは従来モデルと比べて、「精度が高く高速で汎用性が高いモデル」。BERTやGPTなど最新モデルに応用されている。
- 従来モデルの問題が起きていた理由はRNNを利用していたから。「そもそもRNNを使わない」という方法で解決したのがTransformer。
- RNNは文頭から順番に単語を一つずつ処理 に対して、Transformerは単語そのものに情報を詰めこむことで順番に処理する必要がなくなった。単語の順番情報をPositional Encodingで、文脈をMulti-head Attentionで埋め込む。その上でシンプルな全結合層で処理する。
TransformerとLLMアーキテクチャの違い、LLMがどうやって作られているか?については、この記事で解説しています。

ここまでの学習、お疲れさまでした。そして本記事を最後まで読んでいただきありがとうございました!
ここからは、おすすめの書籍を紹介します。この記事で興味を持った方は、本を読めばさらに実践的な力が手に入るはずです。
特徴
・LLMの仕組みを、数式を使わず図で解説
・LLMを使った自動化をPythonコードで実装
今からLLMを体系的に学びたい、LLMを使った自動化や新機能を実装してみたいという方におすすめです。
以下のAmazon概要欄にて本の一部が無料で公開されていますので、ぜひ覗いてみてください。



自然言語処理のおすすめ書籍・オンラインコースは上のページでまとめて紹介しています。
テーマごとに厳選した書籍、そもそもNLPは何から学べば良いか?などを網羅的にまとめています。
「NLPを最短で体系的に学びたい」という方は是非ご覧ください。
おすすめの勉強ステップ
1. 概要・大枠を知る。
Webサイトなどで概要を理解する(本サイトはこのステップの支援を目指しています。)
詳細を学ぶ際に、より効率良くインプットできる。
2. 詳細を知る、理解を深める。
書籍、論文でより詳しく学ぶ。
3. 実践・アウトプット
SignateやKaggleに参加してモデルを作ってみる、勉強したことをブログにまとめる。
個人的には、データサイエンス、特にNLP関係の本は難しく、いきなり本を読むと挫折してしまう人が多いと感じています。
このサイトで概要・全体像を理解してから本を読むことで、より理解しやすく挫折も少なくなるはずです。(その役に立てるよう記事を執筆していきます!)

このサイト、Twitterについて
このサイトでは、NLP関係の解説記事をわかりやすく図解していきます。
「他のサイトの解説は難しすぎる」「もっと直感的に理解したい」という方々の役に立てるように解説していきます。
是非、お気に入り登録、Twitterのフォローをお願いします。Twitterでは、投稿のお知らせ、NLPの最新情報などを発信しています。
参照文献
原論文
Attention Is All You Need(https://arxiv.org/abs/1706.03762)
Sequence to Sequence Learning with Neural Networks(https://papers.nips.cc/paper/2014/hash/a14ac55a4f27472c5d894ec1c3c743d2-Abstract.html)
Webサイト
https://www.ibm.com/blogs/watson/2020/12/how-bert-and-gpt-models-change-the-game-for-nlp/