
こんにちは!自然言語処理(NLP)・大規模言語モデル(LLM)の解説記事や書籍を書いている、
すえつぐです!
お知らせ:著書 『誰でもわかる大規模言語モデル入門』 を日経BPより出版しました。
こんにちは!自然言語処理(NLP)・大規模言語モデル(LLM)の解説記事や書籍を書いている、
すえつぐです!
お知らせ:著書 『誰でもわかる大規模言語モデル入門』 を日経BPより出版しました。
Attentionは自然言語界のブレイクスルーと言われ、BERTやGPT-3といった最先端技術を理解する上で必須の仕組みです。
このページでは「Attention」についてわかりやすく、そして深く解説していきます。
答えは「likes」です。みなさんは頭の中でどうやって翻訳しましたか?
多くの人が、「後半部分だけ見て訳した」のではないでしょうか。
実際、この英文は後半部分だけ見れば訳すことができます。
エミリーは岩手のりんご農家で生まれ育ったため、毎日りんごを食べていたし、もちろんエミリーはりんごが好きだ。
翻訳文
Emily was born and raised in an apple farm in Iwate, Japan, so she ate apples every day, and of course Emily ( ) apples.
このように、「重要な情報だけ注目(Attention)して考える」ということは人間が無意識に、自然に行っていることです。
もうここまで言ったら多くの方がお気付きかもしれません。
この「重要な情報だけ注目(Attention)して考える」をAIにもできるようにしたのがAttentionという仕組みなのです。
他にも、画像処理でAttentionを使った場合でも、以下のように重要な情報に注目することができます。

上の画像では、画像から「フリスビー」と人間二人に注目していることがわかります。
このように、人間が無意識に行なっている「このタスクではこの部分が重要だな。」ということをAIに理解させる仕組みが、Attentionなのです。
Attentionと従来手法の比較
ここまでで、Attentionの概要を理解できたと思います。
ここからは、従来手法とAttentionを使用したモデルを比較して、より詳しくAttentionを理解していきましょう。タスクは引き続き翻訳タスクを扱います。
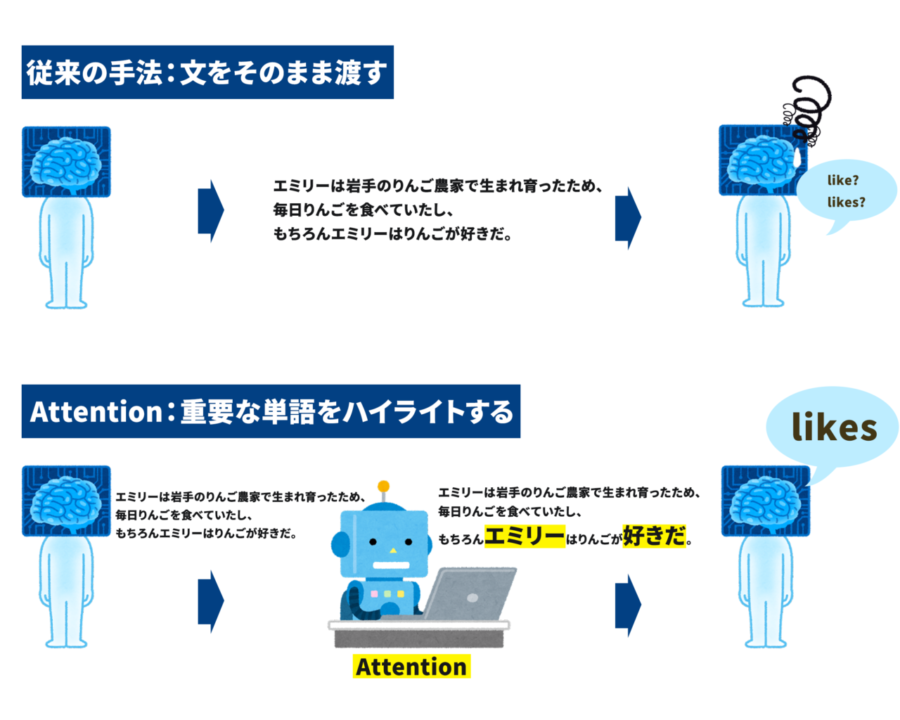
図のように、従来手法は文をそのまま処理していました。短い文は正確に翻訳できますが、今回のような長文では精度が落ちてしまいます。
論文でも従来手法は30文字を超えると急激に精度が落ちることが指摘されていました。
一方、Attentionを使用したモデルは「エミリー」と「好きだ」を重要単語としてハイライトします。
これによって重要な単語に注目(Attention)でき、長文であっても正確に翻訳することができます。
ここまでのまとめ・AttentionはAIに「そのタスクには、どの単語が重要か、注目(Attention)すべきか」を教える仕組み。
・この仕組みのおかげで長文でも精度が落ちなくなった。
ATTENTIONが自然言語界のブレイクスルーと言われている理由
ここまでで、Attentionの仕組みを解説しました。
では、Attentionの開発は自然言語処理(NLP)にどのような影響を与えたのでしょうか。
ここからはNLPにおけるAttentionの重要性について解説していきます!
近年のNLPの急発展の根底にあるのがAttention
AttentionがNLPのブレイクスルーと言われる理由は、BERT、GPT-3などの最先端ライブラリに繋がる重要な仕組みだからです。
Attentionは2015年に発表。そこから自然言語処理界は一気に発展していきます。
発表されて2年後にはAttentionを元にして作られた「Transformer」が発表されました。
Transformerの論文タイトルは「Attention Is All You Need」。
Attentionを更に進化させたMulti-head Attentionという仕組みが使用されました。
![]()
ご存知の方も多いと思いますが、このTransformerを基に強力なライブラリ、BERTやGPT-3が誕生しました。
こういった近年のNLPの急発展の根底にあるのがAttentionです。そのため、Attentionは自然言語界のブレイクスルーと言われているのです。
Transformerに関してはこの記事で、より詳しく解説しています。Attentionと関連が深く、Transformerも自然言語処理の必須知識です。是非チェックしてみてください。
NLPの発展を図解
この自然言語界の発展は、移動手段の発展に例えると直感的にわかりやすいかもしれません。

原論文を元に、数式でATTENTIONの仕組みを深く解説

ここからは原論文を元に、Attentionを理解する上で重要な数式を解説していきます。 もちろん、少し難しい内容になりますが、数学のバックグラウンドがない方々でも理解できるように易しく解説していきます。
本章をしっかり読み、理解することができれば、Attentionを数式で理解・説明することができるようになるはずです。また、原論文を読む前に本章を読むことで、大まかな内容を理解でき原論文をスムーズに読むことができると思います。
流れとしては以下のように解説していきます。
②Attentionの肝となる部分に注目して解説
この章を理解すれば数式でAttentionを理解・説明できるようになるはずです。
ATTENTIONの全体的な流れ
まず、Attentionの全体の流れを解説していきます。
原論文で紹介された、Attentionを組み込んだモデルは「RNNsearch」と呼ばれます。このモデルは先行研究のシンプルなEncoder-Decoderモデル、「RNN Encoder-Decoder」をベースとして作られました。
つまり、先行研究の「RNN Encoder-Decoder」を改善しつつ、Attentionを追加したモデルが「RNNsearch」です。
RNNsearchとはAttentionの少しややこしいところは、Attention自体はNLPモデルではないということです。Attentionは仕組み(アーキテクチャ)であり、それを組み込んだモデルが「RNNsearch」となっています。
簡単なおさらい:Encoder、DecoderとはEncoder:入力された文や単語などをAIが処理できるように変換する
EncoderとDecoderに分けてAttentionの仕組みを解説
ここからは、EncoderとDecoderに分けて先行研究とAttentionのモデルを比較して解説していきます。(原論文と同じように翻訳タスクを使います)
先行研究:RNN Encoder-Decoder
- Encoder
入力単語(x)をRNNで固定次元の意味ベクトル(c)に変換 - Decoder
意味ベクトル(c)と隠れ層(Si)とそれまでの単語(yi-1)を入力に、RNNで単語(p(yi))を出力する
原論文:RNNsearch
- Encoder
入力(x)をBiRNN(双方向RNN)で前後の文脈を加味した単語ベクトル(hi)に変換 - Decoder
Attention機構で単語ベクトル(hi)を文脈ベクトル(ci)に変換。「どの単語に注目(Attention)すべきか」を重み付け(α)する。これこそがAttention。
原論文から引用 文脈ベクトル(ci)、隠れ層(Si)、それまでの単語(yi-1)を入力に、RNNで単語確率(p(yi))を出力する
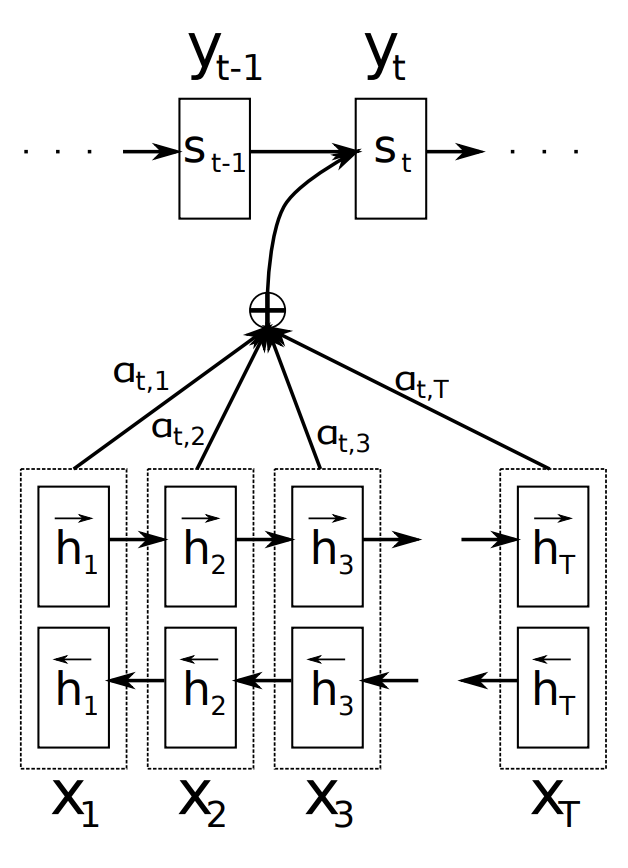
従来のRNNモデルとAttentionを組み込んだRNNモデルの違い
まとめると、先行研究では全ての単語に同じ固定次元の意味ベクトル(c)を作り、そのままRNNに使用していました。
それに対して、
Attentionのモデルでは単語ごとに、どの単語に注目するべきかを加味した文脈ベクトル(ci)を作り、RNNに使用しています。
この意味ベクトル(c)を文脈ベクトル(ci)に変更することで、それまでの課題だった「長文になると精度が落ちる」という課題を克服しました。
次の章ではこの文脈ベクトル(ci)について数式で理解してきます。
ATTENTIONで重要な式:文脈ベクトル(CI)について数式で理解する
前章で説明してきた通り、attentionの肝である文脈ベクトル(ci)を求める式について説明していきます。
まずそれぞれの係数の役割を整理していきます。
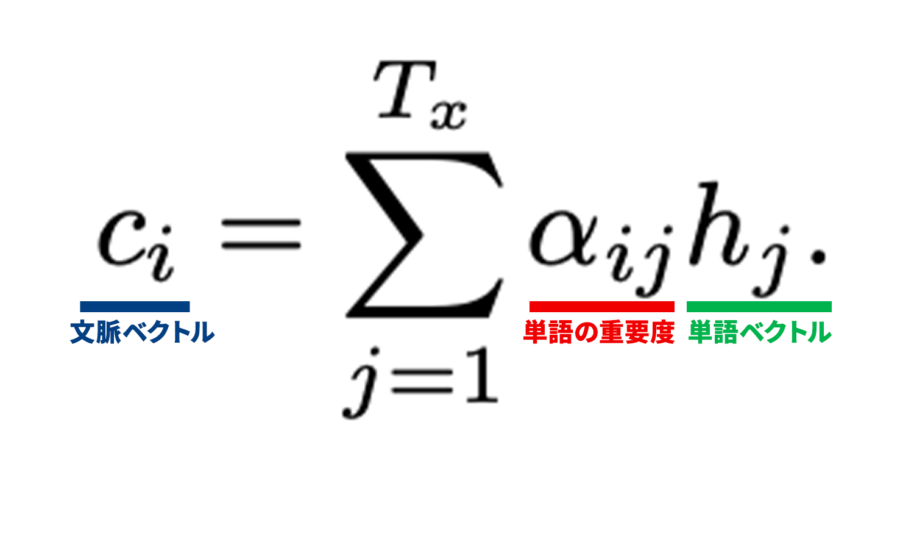
ci:文脈ベクトル
文脈を加味して、「そのタスクにはどの単語が重要か」という情報が入っている。翻訳の場合、「好きだ」を訳すためには「主語」と「好きだ」が重要であるという情報が入っているイメージ。
αij:単語の重要度
その単語がそのタスクに対して、どれくらいの重要かを表す重み。0〜1の値を持つ。詳しくは後述。
hj:単語ベクトル
Encoderの双方向RNNによって、その単語だけでなく前後の単語の情報も入っているベクトル。
つまり文脈ベクトル(ci)を求めるために、
「単語ベクトル(hj)に、その単語の重要度(αij)を重み付けした値の総和(Σ)を出す」
ということです。
補足:ΑIJ(単語の重要度)の式の解説
補足としてαijについても簡単に解説していきます。αijの式は以下のようになっています。
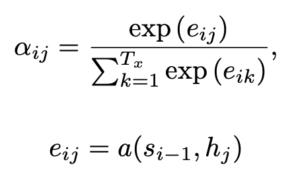
これはSoftmaxの式なので、eijをsoftmaxで計算していることがわかります。
(softmaxについてはこのページで解説しています)
そしてそのeijは、隠れ層(Si-1)と単語ベクトル(hj)を計算し「単語j付近の入力と単語iの出力がどの程度一致しているかのスコア」を出しています。
また、eijの式など、より詳しく学びたい方は原論文を読んでみてください。(リンクは下の方に添付しています)
POINT・従来のRNNモデルを改善するために、RNNモデルにAttention機構を追加した。
・従来は各単語で同じ意味ベクトル(c)を使用。Attentionでは各単語ごとに文脈ベクトル(ci)を使用する。
・文脈ベクトル(ci)は単語に対してαで重要度の重み付けをしたもの。
ここまでの学習、お疲れさまでした。そして本記事を最後まで読んでいただきありがとうございました!
ここからは、おすすめの書籍を紹介します。この記事で興味を持った方は、本を読めばさらに実践的な力が手に入るはずです。
特徴
・LLMの仕組みを、数式を使わず図で解説
・LLMを使った自動化をPythonコードで実装
今からLLMを体系的に学びたい、LLMを使った自動化や新機能を実装してみたいという方におすすめです。
以下のAmazon概要欄にて本の一部が無料で公開されていますので、ぜひ覗いてみてください。

残念ながらAttentionだけに関する書籍はありませんが、以下の書籍でAttentionとTransformer両方を学ぶことができます。



自然言語処理のおすすめ書籍・オンラインコースは上のページでまとめて紹介しています。
テーマごとに厳選した書籍、そもそもNLPは何から学べば良いか?などを網羅的にまとめています。
「NLPを最短で体系的に学びたい」という方は是非ご覧ください。
おすすめの勉強ステップ
1. 概要・大枠を知る。
Webサイトなどで概要を理解する(本サイトはこのステップの支援を目指しています。)
詳細を学ぶ際に、より効率良くインプットできる。
2. 詳細を知る、理解を深める。
書籍、論文でより詳しく学ぶ。
3. 実践・アウトプット
SignateやKaggleに参加してモデルを作ってみる、勉強したことをブログにまとめる。
個人的には、データサイエンス、特にNLP関係の本は難しく、いきなり本を読むと挫折してしまう人が多いと感じています。
このサイトで概要・全体像を理解してから本を読むことで、より理解しやすく挫折も少なくなるはずです。(その役に立てるよう記事を執筆していきます!)

原論文
Neural Machine Translation by Jointly Learning to Align and Translate