
こんにちは!自然言語処理(NLP)・大規模言語モデル(LLM)の解説記事や書籍を書いている、
すえつぐです!
お知らせ:著書 『誰でもわかる大規模言語モデル入門』 を日経BPより出版しました。
RNNを自然言語処理に適応したモデル、「RNNLM」。
RNNLMは従来モデルより「軽量かつ高精度」を実現した革新的なモデルで、それ以降に誕生するモデルにも広く応用されました。
またRNNLMは、仕組みが非常にシンプルで理解しやすいのが特徴です。そしてRNNLMを理解できれば、RNNLMベースのモデルであるAttentionやGRUなども理解しやすくなるでしょう。
このページではそんなRNNLMについて「図解でわかりやすく」、そして「数式を使って深く」解説していきます。
ざっくりと概要を理解したい人は「第1章 RNNLMをわかりやすく図解」まで、数式まで詳細に理解したい人は「第2章 原論文を元に、数式でRNNLMを深く解説」まで読むことをお勧めします。
RNNLMをわかりやすく図解
ここではRNNLMについてイラストを使って仕組みと時代背景をわかりやすく解説していきます!
従来モデル、n-gramとの比較
RNNLMが誕生するまでは、「n-gram」を使ったモデル(back-offモデル)が主流でした。そこで、原論文と同じようにn-gramとRNNLMを比較しながらRNNLMの仕組みと凄さを解説していきます。
まず、n-gramの仕組みと問題点について簡単に解説していきます。
n-gramとは文をn単語(文字数の場合もある)で区切って文脈を読み取るという仕組みです。
ここでは原論文と同じく「次の単語予測」をタスクを使って、n-gramとRNNLMを比較していきます。
今回のタスク
今回解説で使用するタスクは原論文でも使われている、「次の単語を予測する」というタスクです。
例えば、この文の次の単語は何が来ると予測できますか?(なんだこの例文?と思われるかもしれませんが、この後解説するのでスルーしてください、、笑)
「このお好み焼きソースは安全性を示す確かなソースがあるためこのソースは・・・」
「安全だ」「危険ではない」「使用できる」といったところが有力でしょうか。このように、それまでの文脈を材料に、次に来る単語を予想する、というのが今回のタスクです。
まず従来モデルのN-GRAMにこのタスクを解かせてみましょう。そうすると以下のイラストのようになります。今回はN-GRAMのNは3にします。(文を3単語ずつに区切る)
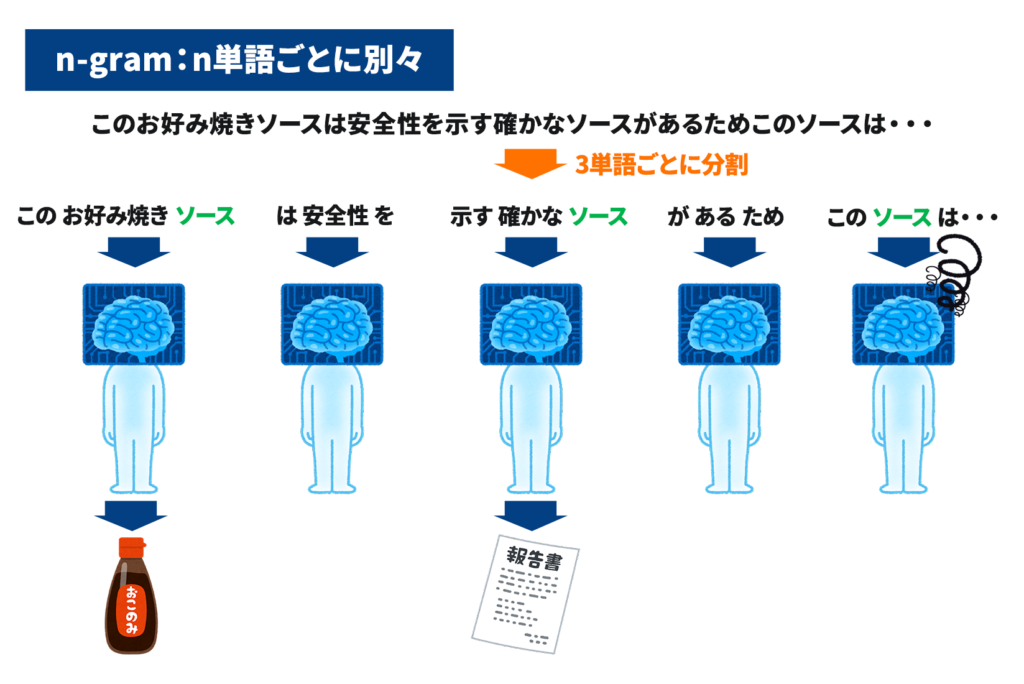
イラストのように、n-gramは文をn単語ごと(今回は3単語)に区切り文脈を読み取っていきます。
n-gramの特徴と問題点を理解するために「ソース」という単語に注目してください。
今回の文では異なる意味の「ソース」が存在しています(お好み焼きソースと情報源)。n-gramでは全く同じ「ソース」という単語でも一緒に区切られた前後の単語から意味を読み取ります。今回の場合、前後の単語の「お好み焼き」や「示す」などの単語を読み取ることで、正しく区別できていることがわかります。
しかし、n-gramには問題点があります。イラストの三つ目の「ソース」を見てください。n単語の中には「この」と「は」しか入っておらず、十分な情報が入っていません。こういった情報が不足している場合、n-gramでは正しく意味を読み取ることができません。
このようにn-gramでは、「n単語に分けた中に十分な情報がないと、正しい意味を読み取れない」という大きな問題点がありました。
そして、この問題を解決したのがRNNLMというわけです。
RNNLMの仕組み・RNNLMが改善したこと
前述したように、n-gramの問題点は、「n単語に分けた中に十分な情報がないと、正しい意味を読み取れない」でした。
そこで、RNNLMは「それまでの文全体の流れから文脈を理解する」という方法でこの問題を解決しました。n-gramが限られた単語から文脈を読み取るのに対して、それまでの文全体から文脈を読み取ることで文脈をより正しく理解しようと試みたのです。
つまり、n単語ごとに別々に単語を読み取るのに対して、RNNは情報をリレー形式で渡すことで文脈を読み取るというモデルなのです。イラストで見ていきましょう。
イラストのようにRNNは、「それまでの文全体の流れ」という情報を渡していきます。これによって離れた位置にある単語の情報も読み取ることが可能になりました。n-gramと比較して文全体を理解できるようになり、RNNLMは従来のモデルよりも高い精度を出すことができたのです。
- RNNLM以前のn-gramには「n単語に分けた中に十分な情報がないと、正しい意味を読み取れない」という問題点があった。
- RNNLMは「それ以前の文脈を情報として渡す」ことによってn-gramの問題点を解決し高精度を出した。
RNNLMの課題点。
RNN LMにも課題が残されていました。それは「文が長くなりすぎると精度が下がる」という点です。
この課題は後にAttentionによって改善されました。詳しく知りたい方はこのページで詳しく解説しています。是非読んでみてください。

RNNLMが与えた影響・RNN以降のモデル
ここまででRNNLMの仕組みと凄さについて説明しました。ここからは、RNNLMが自然言語界に与えた影響について解説していきます。
RNNLMが登場するまでは、前述したn-gramの問題点を解決するために「数の暴力」とも言える方法が主流でした。具体的には、n-gramの「n単語に分けた中に十分な情報が入っていないと正しく認識できない」という課題を克服するために、「n(単語数)を増やす」や「モデルの学習データを増やす」といった方法が研究されていました。
つまり、「モデルを巨大化させて精度を上げていく」という流れがあったわけです。
それに対して、RNNLMはニューラルネットを使ったシンプルなモデルで高い精度を叩き出しました。このようにRNNLMはそれまでの常識を覆す方法で、「軽量化&高精度化」を実現しました。 (原論文でも「RNNLMは学習データを増やすことが唯一の方法であるという神話を覆した」という内容が書かれています。)

イラストのようにn-gramを使ったスケール重視の時代から、RNNLMが発表されてからは「ニューラルネットワークを使ったモデル」へ時代は変わっていきました。
RNNLMを元にして、AttentionやGRUなどが次々と開発されていきました。RNNLMは「次の単語予測」でしたが、Attentionでは「翻訳タスク」で従来モデルに勝利するなど、様々なタスクでニューラルネットモデルが広がっていきます。
そしてRNN主流の時代に終止符を打ったのがTransformerでした。Transformerの原論文のタイトルは「Attention is all you need」、Attentionだけで大丈夫、RNNはもういらないよという挑戦的なタイトルでした。Transformerが誕生してからは、それをベースにしたBERT、GPT-3、PaLMなどの強力なモデルが開発されました。
ここからは少し余談です。最新モデルのBERTやGPT-3、PaLMなどは「パラメータや学習データを増やす」ことで精度を向上し続けている側面があります。実際にGPT-3(2020年発表)のパラメータは「1750億」、PaLM(2022年発表)のパラメータは「5400億」です。どんどんモデルが巨大化して行っていることがわかりますよね。
この流れ、RNNLM以前のn-gramと似ていませんか?
n-gramベースの巨大化の流れを覆してRNNLMが「軽量化&高精度化」を実現したように、TransformerベースのGPT-3やPaLMといった巨大なモデルを全く新しい、革新的な方法で抜き去るモデルが近数年で出てくる可能性があると感じています。
(実際にBERTベースのモデルではALBERTなど、軽量化&高精度化への動きがあるようです)
RNNLMはそれまでの「モデルの巨大化」の流れを断ち切って、「軽量化&高精度化」を実現。Transformerが誕生するまで主流のモデルになった。
原論文を元に、数式でRNNLMの仕組みを深く解説
ここまでで、RNNLMの概要は理解できたと思います。ここからは原論文を元に、RNNLMを理解する上で重要な数式を解説していきます。
もちろん、本章は少し難しい内容になりますが、できるだけ噛み砕いて説明しますので高度な数学の知識は必要ありません。
本章をしっかり読み理解することができれば、RNNLMを数式で理解・説明することができるようになるはずです。
また研究などで原論文を読む予定の方は、原論文を読む前に本章を読むことで大まかな内容を理解でき、原論文をスムーズに読むことができると思います。
この章を理解すれば数式でRNNLMを理解・説明できるようになると思います。
RNNLMは非常にシンプルなモデルのため、全ての数式を一つずつ順番に説明していきます。
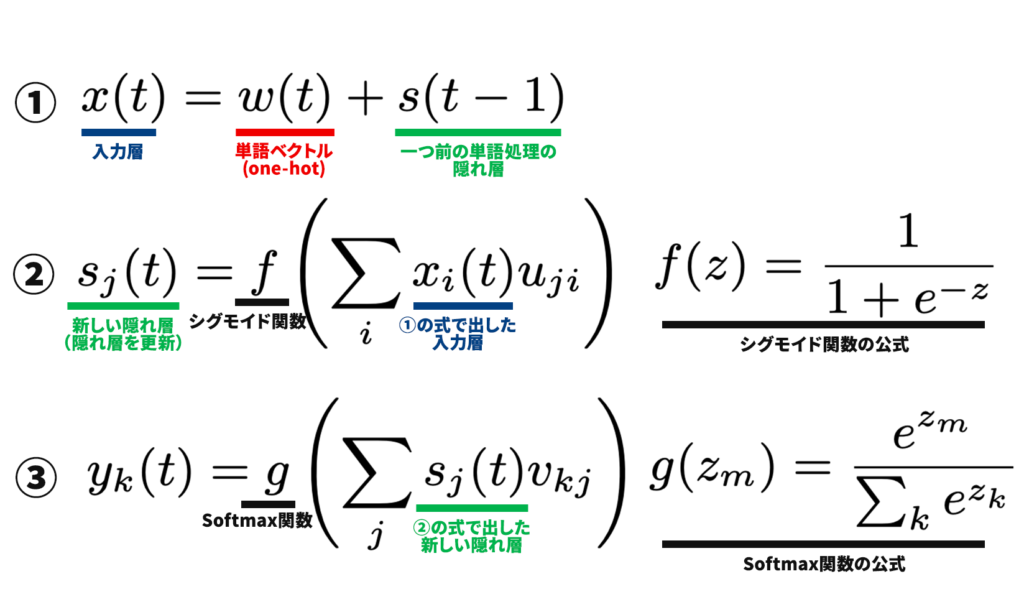
上の式がRNNLMの重要な式全てです。一見、難しく見えるかもしれませんが、非常にシンプルなものです。
ざっくりとそれぞれの式の説明をすると、下のようになります。
式①で情報を入力
式②で入力した情報を処理
式③で処理した情報を出力
順番に見ていきましょう。
式①:入力
入力した単語ベクトル(w(t))、一つ前の層から渡された隠れ層(s(t-1))から、入力層(x(t))を出力。fはシグモイド関数。
- 単語ベクトル(wt)
単語をワンホットエンコーディングしたベクトル - 隠れ層(s(t-1))
一つ前の層で出力された隠れ層。これが「それまでの文全体の流れ」の情報を持っている。この情報を更新して次の層に渡すことで、「文全体の流れ」を更新し続けることができる。
式②:処理
式①で出した入力層(x(t))と隠れ層(s(t-1))から、新しい隠れ層(s(t))にを出力。(この数式は次の章で解説)
式③:出力
新しい隠れ層(s(t))から、次の単語の予測確率(yk(t))を出力。ソフトマックス(g)で合計が1になるように0-1の値に変換。
- 次の単語の予測確率(yk(t))
出力結果。次の単語になんの単語が来る可能性が高いのかを示す。
このように入力した単語ベクトルと隠れ層という二つのベクトルを元に、処理を行うだけとかなりシンプルなモデルになっています。
- RNNLMは入力→処理→出力という非常にシンプルなモデル。
- 隠れ層(si)を更新し続けながら渡すのがRNNLMの肝。
まとめ
1章
- RNNLM以前のn-gramには「n単語に分けた中に十分な情報がないと、正しい意味を読み取れない」という問題点があった。
- RNNLMは「それ以前の文脈を情報として渡す」ことによってn-gramの問題点を解決し高精度を出した。
- RNNLMはそれまでの「モデルの巨大化」の流れを断ち切って、「軽量化&高精度化」を実現。Transformerが誕生するまで主流のモデルになった。
2章
- RNNLMは入力→処理→出力という非常にシンプルなモデル。
- 隠れ層(si)を更新し続けながら渡すのがRNNLMの肝。
参考資料・おすすめの参考書
ここまでの学習、お疲れさまでした。そして本記事を最後まで読んでいただきありがとうございました!!
ここでは更に学びを深めたい方々のために、おすすめの参考書と勉強法を紹介します。
おすすめの参考書
RNNを含む、ディープラーニングをより詳しく学びたい方は、以下の書籍で詳細を学び、実装してみるのがおすすめです。


自然言語処理のおすすめ書籍・オンラインコースはこのページでまとめて紹介しています。
「NLPを最短で体系的に学びたい」という方のために、テーマごとに厳選した書籍、そもそもNLPは何から学べば良いか?などを網羅的にまとめています。是非ご覧ください。
おすすめオンラインコース
動画・オンラインコースで学びたい、機械学習からディープラーニングまでを網羅的に学びたい、復習したいという方には以下のUdemyがおすすめです。
【世界で55万人が受講】データサイエンティストを目指すあなたへ〜データサイエンス25時間ブートキャンプ〜 ![]()
このUdemyのコースは統計学・数学から機械学習・ディープラーニングまでの広い範囲を、非常にわかりやすくまとめた入門コースです。
勉強・復習に便利なのはもちろん、私はチームで共通認識を作るためにチーム全員でこのコースを購入しました。
おすすめの勉強ステップ
1. 概要・大枠を知る。
Webサイトなどで概要を理解する(本サイトはこのステップの支援を目指しています。)
詳細を学ぶ際に、より効率良くインプットできる。
2. 詳細を知る、理解を深める。
書籍、論文でより詳しく学ぶ。
3. 実践・アウトプット
SignateやKaggleに参加してモデルを作ってみる、勉強したことをブログにまとめる。
関連記事|【完全マニュアル】技術ブログを始めるべき理由と始め方。メリット・収益・書き方を徹底解説
個人的には、データサイエンス、特にNLP関係の本は難しく、いきなり本を読むと挫折してしまう人が多いと感じています。
このサイトで概要・全体像を理解してから本を読むことで、より理解しやすく挫折も少なくなるはずです。(その役に立てるよう記事を執筆していきます!)
原論文
Neural Machine Translation by Jointly Learning to Align and Translate