
- はじめに
- 2001年 – ニューラル言語モデル(Neural Language models)
- 2008年 – マルチタスク学習(Multi-task learning)
- 2013年 – 単語埋め込み(Word embeddings)
- 2013年 – NLPのためのニューラル・ネットワーク
- 2014年 – sequence-to-sequenceモデル
- 2015年-Attention
- 2015年 – メモリベースのネットワーク(Memory-based networks)
- 2018年 – 事前学習済み言語モデル(Pretrained Language models)
- その他のマイルストーン
- ニューラルネット以外のマイルストーン(Non-neural milestones)
- 謝辞
- 著者について
はじめに
こんにちは!自然言語処理(NLP)・大規模言語モデル(LLM)の解説記事や書籍を書いている、
すえつぐです!
お知らせ:著書 『誰でもわかる大規模言語モデル入門』 を日経BPより出版しました。
近年、BERTやGPT-3など、様々なNLPモデルが開発・使用されていますよね。ただ、「どうやってここまで進化したのか?」、「自然減言語処理(NLP)にはどういった歴史があるのか?」については知らない人も多いのではないでしょうか。
一つ一つのモデルについて理解するだけでなく、そのモデルができた背景や歴史を知ることで、より理解が深まるはずです。
そこで今回は、NLPモデルでも最も主流である、「ニューラルネットワークを使ったNLPモデル」に焦点を当てて、NLPの歴史について解説していきます。
冒頭でも述べたように、この記事を書くにあたって、Googleの研究者であるSebastianさんとステレンボッシュ大学の研究者であるHermanさんの英語記事を翻訳・翻案する許可をいただきました。
この記事は複雑なNLPの歴史を整理し、網羅的に解説したものです。私自身もお気に入りに登録して、何度も読み返しています。(ただ少し難しい内容なので「全部を一気に理解する」というよりは必要なときに見返しています)
きっとこの翻訳記事を読めば、これまでのNLPの知識と知識が繋がり、「このモデルはこういった背景で開発されたモデルだったのか!」など、多くの発見と学びがあるはずです。
本記事を元に、NLPの歴史をギュッと圧縮した年表を制作しました。本記事のお供としてお使いください。

2001年 – ニューラル言語モデル(Neural Language models)
言語モデリング(Language modeling)は、テキストが与えられ、そのテキストの次の単語を予測するタスクです。これは最もシンプルな言語処理のタスクの1つで、インテリジェントキーボード、電子メール応答提案(Kannan et al., 2016)、スペル自動修正などの実用例があります。
補足:言語モデリング(Language Modeling)の例
入力例:「今日は良い天気だ。仕事の後は絶対、______に行こう。」
予想例:「飲み」、「レストラン」、「散歩」など
このように、予測する単語より前の文脈を考慮して、次に来る単語の予測を行うタスクが言語モデリングです。
言語モデリングの研究には長い歴史があります。古典的なアプローチはn-gramに基づき、未知のn-gramを処理するために平滑化が使用されていました(Kneser & Ney, 1995)。
そんな中で、最初にニューラルネットを言語モデリングに使用したのが、2001年にBengio達が提案した、フィードフォワードニューラルネットワーク言語モデルです。(図1)
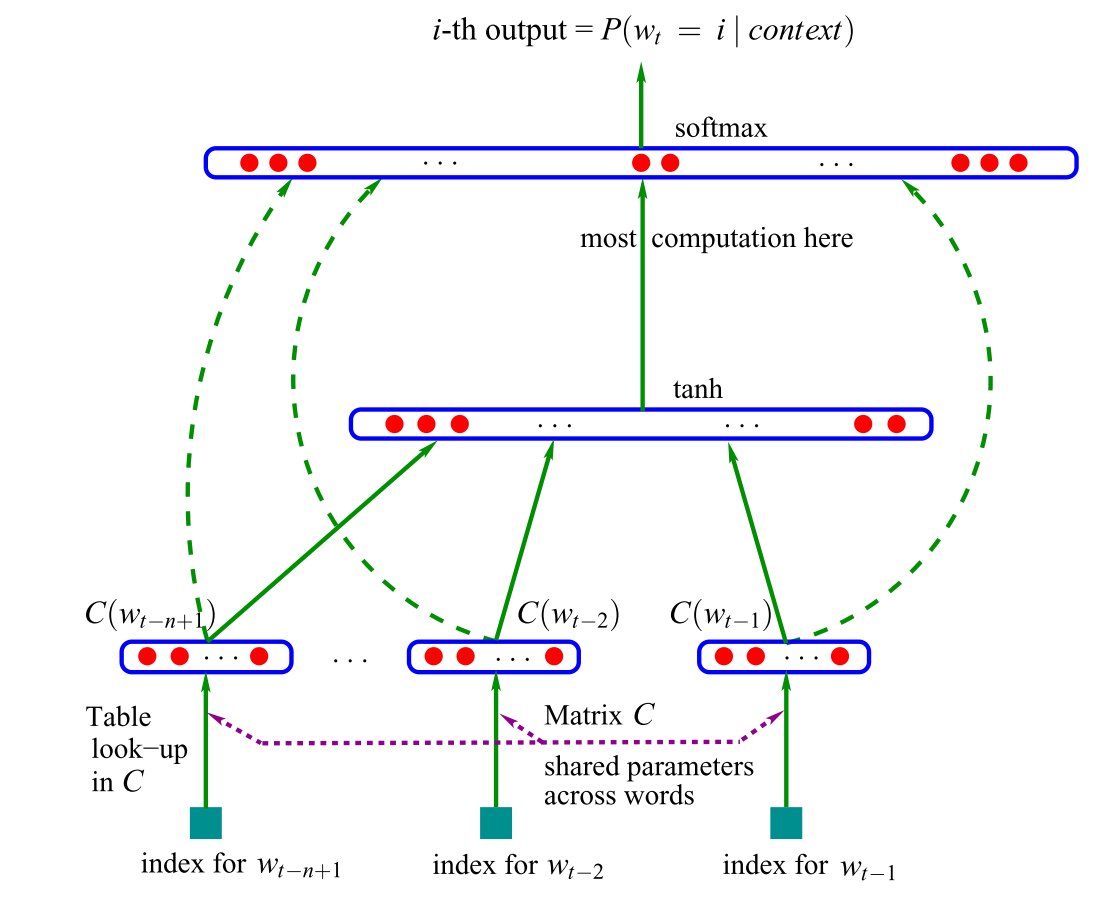
このモデルは、入力値としてテーブルCで検索された、n個の前の単語のベクトル表現を使用します。このようなベクトルは現在、ワードエンベディングと呼ばれています。このワードエンベディングを連結し隠れ層に渡し、その出力がsoftmax層に渡されます。
近年では、フィードフォワードニューラルネットワークは再起型ニューラルネットワーク(RNN; Mikolov et al., 2010)および長・短期記憶ネットワーク(LSTMs; Graves, 2013)に置き換わっています。
加えて、LSTMを拡張した言語モデルも多数提案されています。ただ、新しい言語モデルが多く開発されましたが、古典的なLSTMが強力なベースラインであり続けていました(Melis et al., 2018)。それどころか、Bengioらの最も古典的なフィードフォワードニューラルネットワークでさえ、より洗練されたモデルと競合する場合も報告されていました(Daniluk et al., 2017)。
そのため、言語モデルがどのような情報を捉えているかをより正確に理解することは、活発に取り組まれている研究領域です (Kuncoro et al., 2018; Blevins et al., 2018)。
つまり、古典的なベースモデルの拡張モデルが多く開発されたが、拡張モデルがベースモデルよりも完全に優れているわけではなかった、ということです。
そのため、その原因を探るために「言語モデルがどのような情報を捉えているか」を理解する必要があった、研究が行われていた、ということです。
言語モデリングは、RNNによく使用される学習タスクです。Andrejのブログ記事でこのコンセプトに初めて触れた人も多く、多くの人にインスピレーションを与えました。言語モデリングは教師なし学習の一形態であり、Yann LeCun はこれを予測学習と呼び、常識を獲得するための前提条件として挙げています(NIPS 2016でのCakeスライド)。
最も注目すべき点は、言語モデリングはそのシンプルさにもかかわらず、本記事で取り上げる後の多くの進歩の核となっていることでしょう。例として、以下の3つの技術が言語モデリングを核とした技術です。
- ワードエンベディング:word2vecの目的は、言語モデリングの簡略化です。
- sequence-to-sequenceモデル:一度に1単語ずつ予測しながら、出力シーケンスを生成する。
- 事前学習済み言語モデル:言語モデルを事前に学習し、その得られた表現を転移学習に利用する。
一方で、これは最近の自然言語処理における重要な進歩の多くが、言語モデルの一形態に還元されていることを意味します。
「本当の」自然言語理解を行うためには、テキストのそのままの形式から学習するだけでは不十分であり、新しい手法やモデルが必要になるでしょう。
言語モデリングとは、「テキストが与えられ、そのテキストの次の単語を予測するタスク」というシンプルなタスクです。そして、この言語モデリングをベースに、ワードエンベディングだけでなく、最新の事前学習モデルが開発されています。
つまり、NLPの重要な進歩は「次の単語予測」というシンプルなタスクに基づいていると言えます。それでは「本当の」自然言語理解を行うことは難しいのではないか、ということを筆者は指摘しています。
2008年 – マルチタスク学習(Multi-task learning)
マルチタスク学習とは、複数のタスクで学習させたモデル間で、パラメータを共有するための一般的な手法です。ニューラルネットワークの場合は、異なる層の重みを結びつけることで簡単に行うことができます。マルチタスク学習の考え方は、1993年にRich Caruanaによって初めて提案され、道路追従や肺炎の予測に応用されました(Caruana, 1998)。
直観的には、マルチタスク学習はモデルが多くのタスクに有用な表現を学習することを促します。これは、一般的な低レベルの表現を学習し、モデルの注意を集中させる場合や、学習データの量が限られている場合に特に有効です。(マルチタスク学習のより包括的な概要については、こちらの投稿を読んでみてください。)
例えば、機械翻訳と文書分類という2つのタスクを学習する場合を考えてみましょう。
二つのタスクを学習することで、翻訳タスクで学習した語彙や文法の知識を、文書分類タスクにも応用できます。また、文書分類タスクで学習した意味解析の能力を翻訳タスクにも応用できます。
このように、マルチタスク学習は複数のタスクに対応できるようになるだけでなく、それぞれ単体のタスクの性能も向上できます。
マルチタスク学習は2008年にCollobertとWestonによって、初めてNLPのニューラルネットワークに適用されました。彼らのモデルでは、以下の図2に示すように、ルックアップテーブル(または単語埋め込み行列)を異なるタスクで学習した2つのモデルで共有します(図2)。
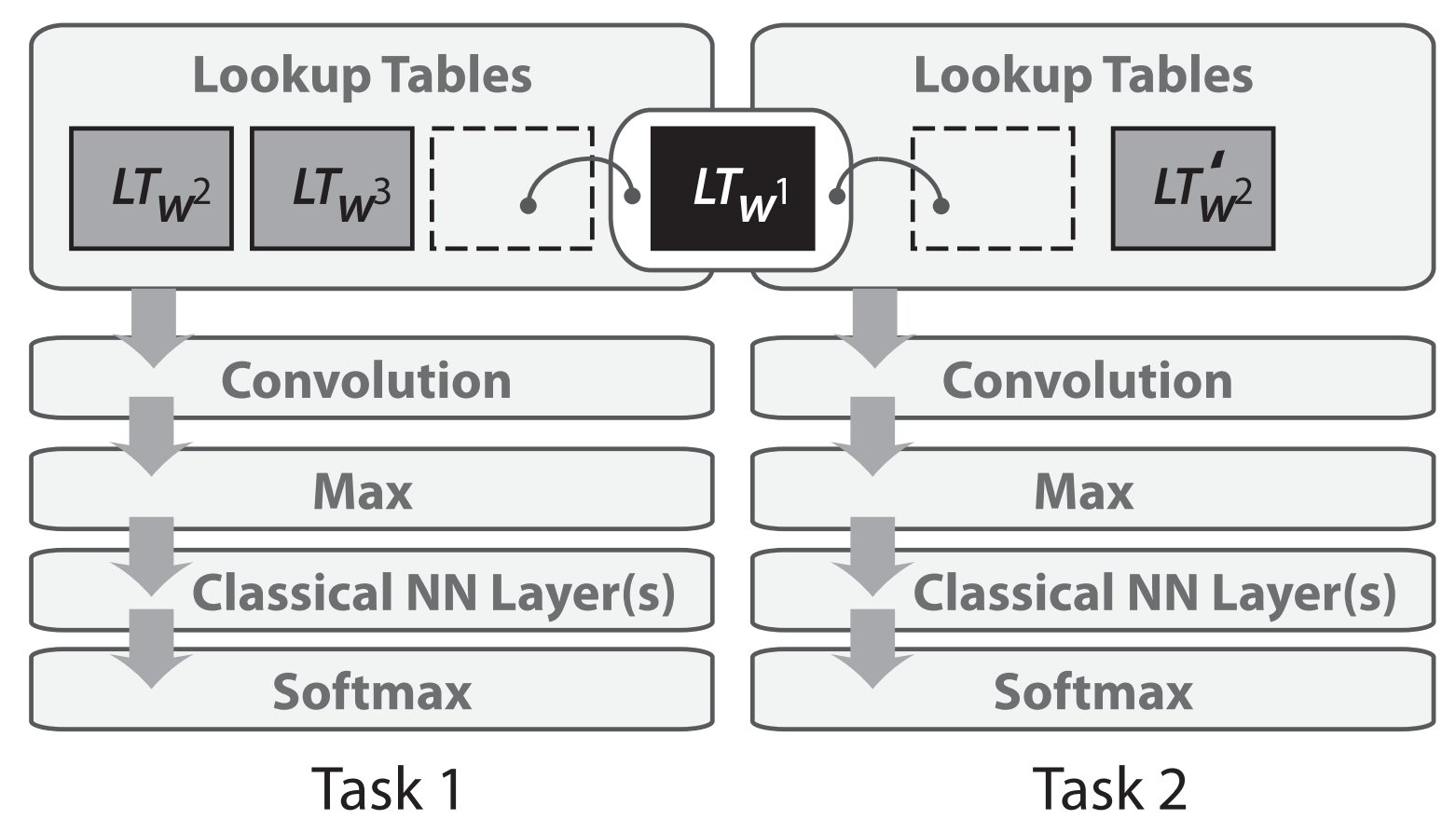
単語埋め込み行列を共有することで、一般的にモデルの中で最も多くのパラメータを占める単語埋め込み行列の一般的な低レベル情報をモデル間で連携し、共有することができます。
また、CollobertとWestonによる2008年の論文は、マルチタスク学習の利用以外にも影響力があることが証明されました。この論文は、単語埋め込み行列の事前学習やテキストへの畳み込みニューラルネットワーク(CNN)の利用など、ここ数年でようやく広く採用されるようになったアイデアの先駆けとなりました。その結果、この論文はICML 2018でtest-of-time賞を受賞しました(論文をコンテクスト化したtest-of-time賞のトークはこちら)。
マルチタスク学習は現在、幅広いNLPタスクで使用されており、既存のタスクや「人工的な」タスクを使用したマルチタスク学習は、NLPのレパートリーとして有用なツールとなっています。様々な補助タスクの概要については、こちらの記事をご覧ください。パラメータの共有は通常事前に定義されていますが、最適化プロセス中に異なる共有パターンを学習することも可能です(Ruder et al.)。
最近では、モデルの汎化能力を測るために複数のタスクで評価されることが多くなったため、マルチタスク学習の重要性が高まり、マルチタスク学習専用のベンチマークが提案されています(Wang et al.2018; McCann et al.)。
マルチタスク学習は、人間で言えば「複数の教科を勉強する」というイメージです。
一つの教科だけでなく、複数教科を勉強することで、その教科ができるようになるだけでなく、他の教科からも学びがあったりしますよね。
NLPの場合でも、従来の一つのタスクだけでなく、複数タスクで学習することで、異なるタスク間で共通した特徴を学習できるようになりました。これにより、複数のタスクに対応できるだけでなく、各タスクでの性能も向上しました。
前章の2001年言語モデリングの「次の単語を予測する」といったシンプルなタスクから、複数のタスクで学習するマルチタスク学習が誕生し、言語モデルの汎用性と性能が向上していったことがわかります。
2013年 – 単語埋め込み(Word embeddings)
テキストを疎なベクトルで表現する、いわゆるBag-of-Wordsモデルは、自然言語処理において長い歴史を持っています。単語の密なベクトル表現、あるいは単語埋め込みは、上で紹介したように2001年には既に使用されていました。
2013年にMikolovらによって提案された主なイノベーションは、隠れ層を取り除き、目的語を近似することで、これらの単語埋め込みの学習をより効率的にすることでした。これらの変更はシンプルなものでしたが、効率的なword2vecの実装とともに、大規模な単語埋め込み学習が可能になりました。
Word2vecには2つの種類があり、図3のように、continuous Bag-of-Words (CBOW)とskip-gramが存在します。この2つは目的が異なり、CBOWは周囲の単語に基づいて中心語を予測し、skip-gramはその逆を行います。
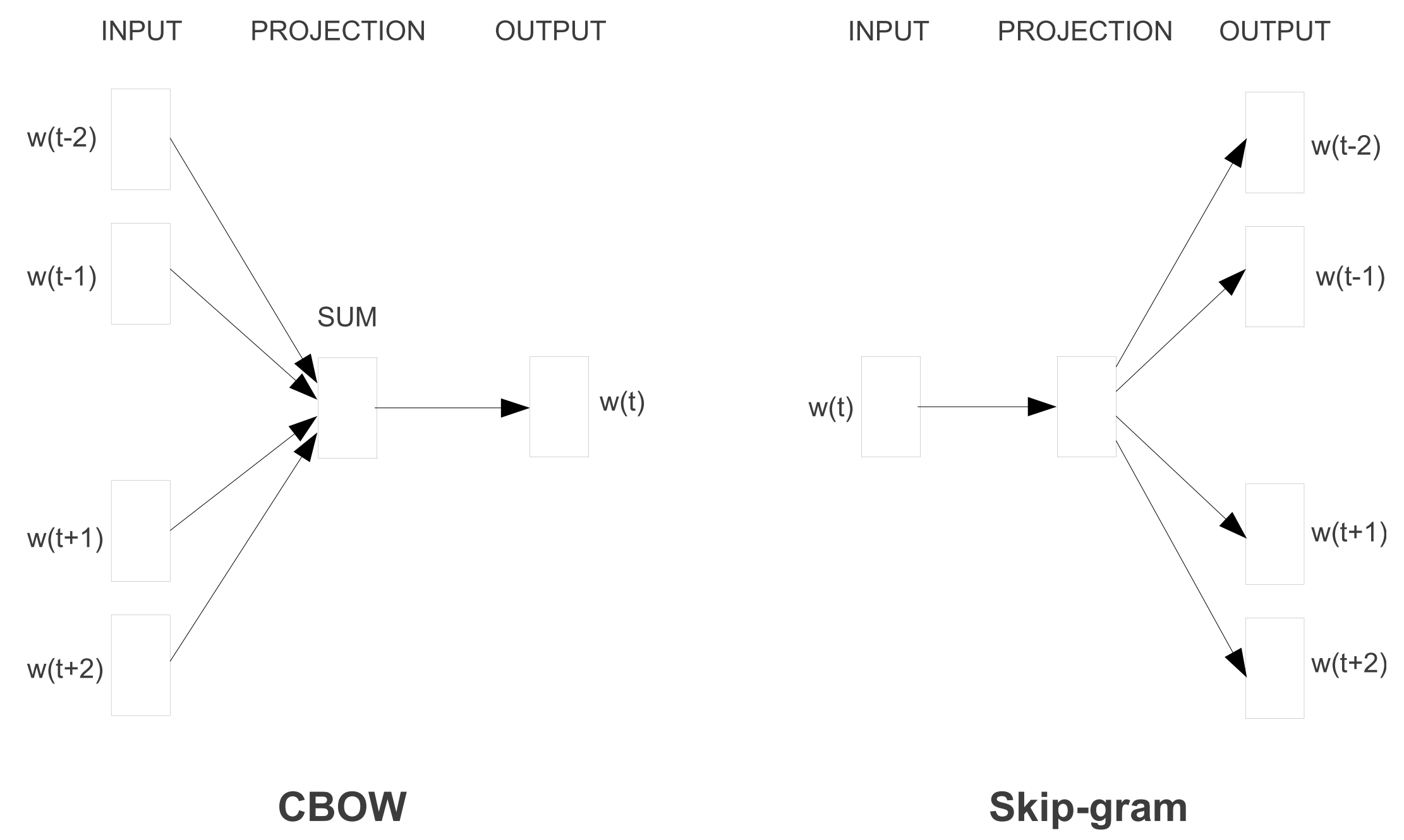
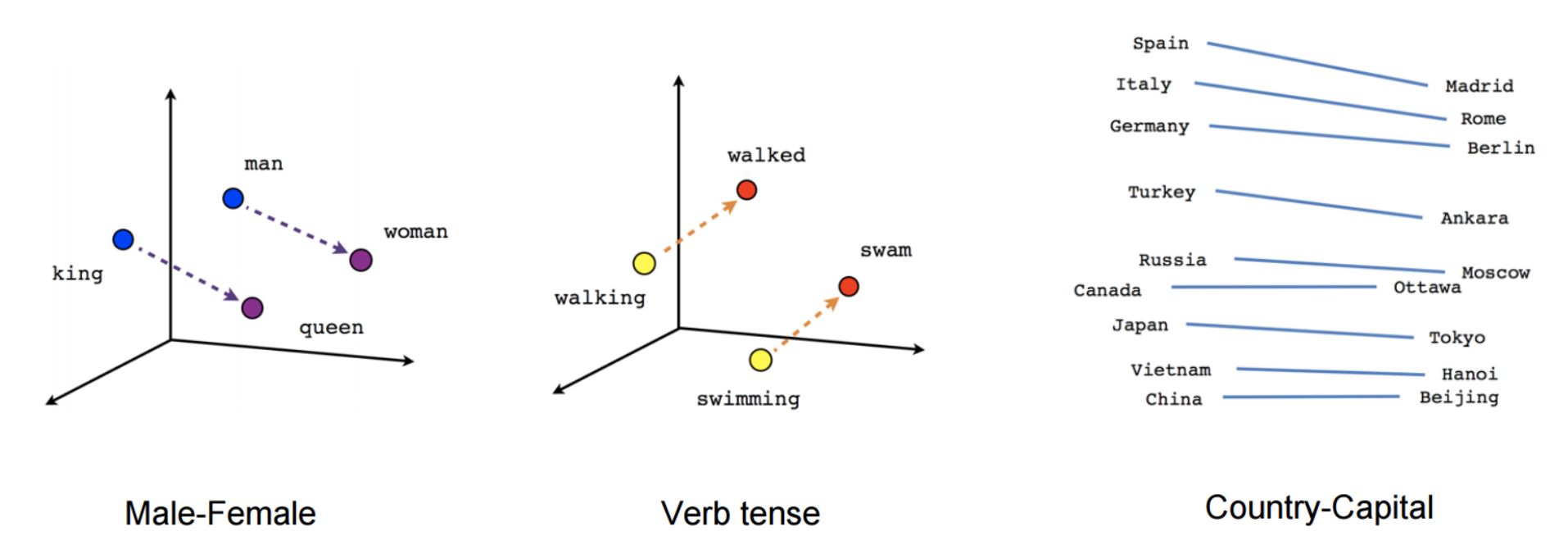
これらの単語間の関係と、その背後にある意味は、単語埋め込みに対する初期の関心を呼び起こし、多くの研究がこれらの線形関係の原因を調査しました(Arora et al.2016; Mimno & Thompson, 2017; Antoniak & Mimno, 2018; Wendlandt et al.2018).
しかし、その後の研究で、学習された関係に偏りがないわけではないことが示されています(Bolukbasi et al.,2016)。それにも関わらず、単語埋め込みが現在のNLPの主力として定着したのは、事前に学習した埋め込みを初期化として使用することで、下流の幅広いタスクでパフォーマンスが向上することが示されたからです。
word2vecが捉えた単語間の関係には、直感的でほとんど魔法のような性質がありましたが、後の研究で、word2vecには本質的に特別なものはないことが示されました。なぜなら、単語埋め込みは行列分解によっても学習でき(Pennington et al, 2014; Levy & Goldberg, 2014)、適切なチューニングにより、SVDやLSAなどの古典的な行列分解アプローチでも同様の結果を達成できることがわかったからです(Levy et al., 2015)。
それ以来、単語埋め込みの様々な側面を探るために多くの研究が行われてきました(元の論文の引用数が驚異的であることが示すように)。いくつかのトレンドと将来の方向性については、この投稿をご覧ください。
多くの改善版の開発にもかかわらず、Word2vecは今日でも人気のある選択肢であり、広く使用されています。局所文脈に基づく埋め込み学習の便利な目的であるネガティブサンプリングによるスキップグラムは、文の表現学習に適用されています(Mikolov & Le, 2014; Kiros et al, 2015)—さらにはNLPを超えて、ネットワーク(Grover & Leskovec, 2016)や生体配列(Asgari & Mofrad, 2015)などにまでも使用されています。
特に興味深い方向性は、異なる言語の単語埋め込みを同じ空間に投影して、(ゼロショット)クロスリンガルな転送を可能にすることです。これは、低リソース言語と教師なし機械翻訳のためのアプリケーションを可能にし(Conneau et al, 2018; Artetxe et al, 2018; Søgaard et al, 2018)、低リソース言語や教師なし機械翻訳への応用の可能性が広がっています(Lample et al, 2018; Artetxe et al, 2018)。より詳しい概要については、(Ruder et al., 2018)をご覧ください。
2013年 – NLPのためのニューラル・ネットワーク
2013年から2014年にかけて、NLPにニューラルネットワークモデルが採用され始めました。特に、リカレントニューラルネットワーク、畳み込みニューラルネットワーク、再帰的ニューラルネットワークの3つが最も広く使われるようになりました。
リカレントニューラルネットワーク(Recurrent neural networks)
リカレントニューラルネットワーク(RNN)は、自然言語処理で多用される、動的な入力系列を扱うのに最適なモデルです。バニラRNN(Elman, 1990)は、すぐに古典的な長・短期記憶ネットワーク(LSTM; Hochreiter & Schmidhuber, 1997)に置き換えられ、LSTMは勾配消失と勾配爆発の問題に対して、RNNより強いことが証明されていました。
そのため、2013年以前はRNNでの学習は難しいとされていましたが、Ilya Sutskeverの博士論文が、この評判を覆す重要なものとなりました。
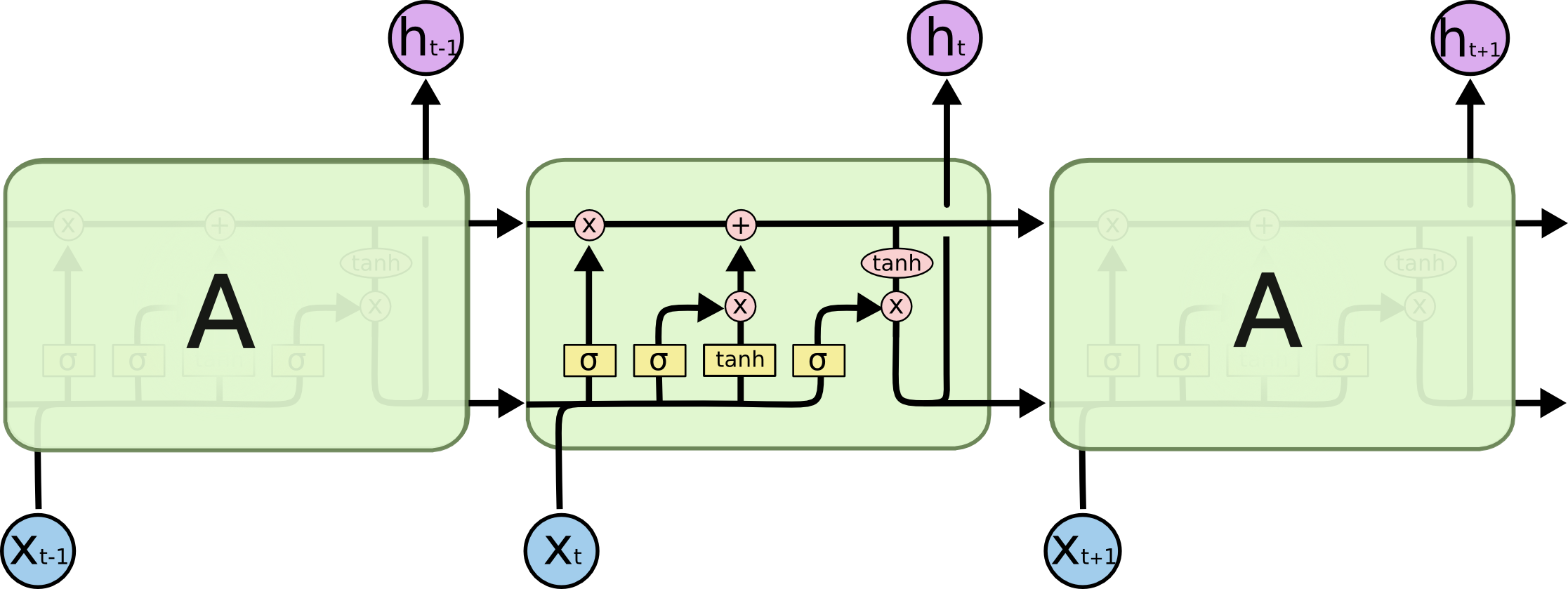
図5は、LSTMのセルを可視化したものです。双方向LSTM (Graves et al., 2013) は一般的に左右両方の文脈を扱うために使用されます。
畳み込みニューラルネットワーク(Convolutional neural networks)
畳み込みニューラルネットワーク(CNN)が画像処理で広く使われるようになったことをきっかけに、CNNのNLPへの応用が試され始めました(Kalchbrenner et al.)。 テキスト用のCNNは2次元でしか動作しないため、フィルターは時間的な次元に沿って移動させるだけで良いという利点がありました。
以下の図は、NLP で使用される典型的な CNN です。
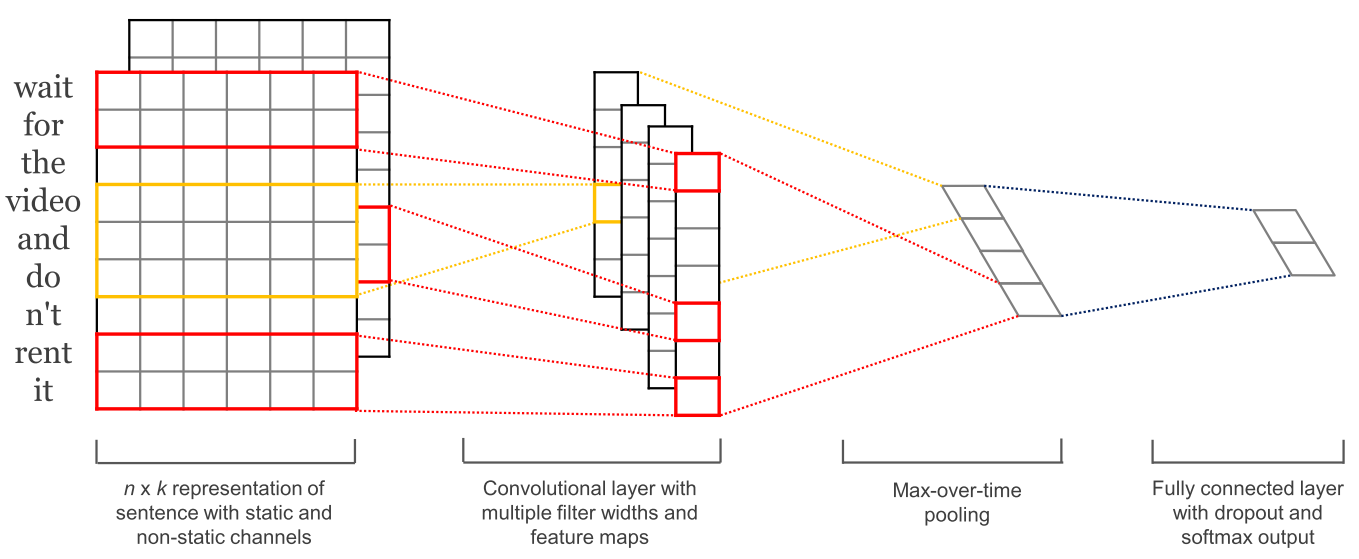
畳み込みニューラルネットワークの利点は、RNNよりも並列化が可能なことです。
RNNは、過去のすべての状態を保持しておく必要があるため、演算量が膨大になりがちです。一方、CNNは、畳み込み層とプーリング層を組み合わせることで、ローカルな情報だけを抽出して処理するため、計算量を削減することができます。また、CNNは、タイムステップごとの状態が(畳み込み演算によって)局所的なコンテキストにのみ依存するため、過去の状態を保持する必要がなく、過去の情報を考慮しなくてもよい、という利点もあります。
加えてCNNは、より広いコンテキストを捉えるために、拡張畳み込みを使用して、より広い受容野で拡張することができます(Kalchbrenner et al.,2016)。また、CNNとLSTMは組み合わせて積み重ねることができ(Wang et al.,2016)、LSTMを高速化するために畳み込みを使用できます(Bradbury et al.,2017)。
再帰的ニューラルネットワーク(Recursive neural networks)
RNNとCNNは、どちらも言語を連続したシーケンスとして扱います。しかし、言語学的な観点からは、言語は本質的に階層的と言えます。単語は高次のフレーズや節の下に構成され、それ自体は一連の生成規則に従って再帰的に組み合わせることができます。文章を配列としてではなく、木として扱うという言語学的な発想から、再帰的ニューラルネットワーク(Socher et al.,2013)が生まれました(図7)。
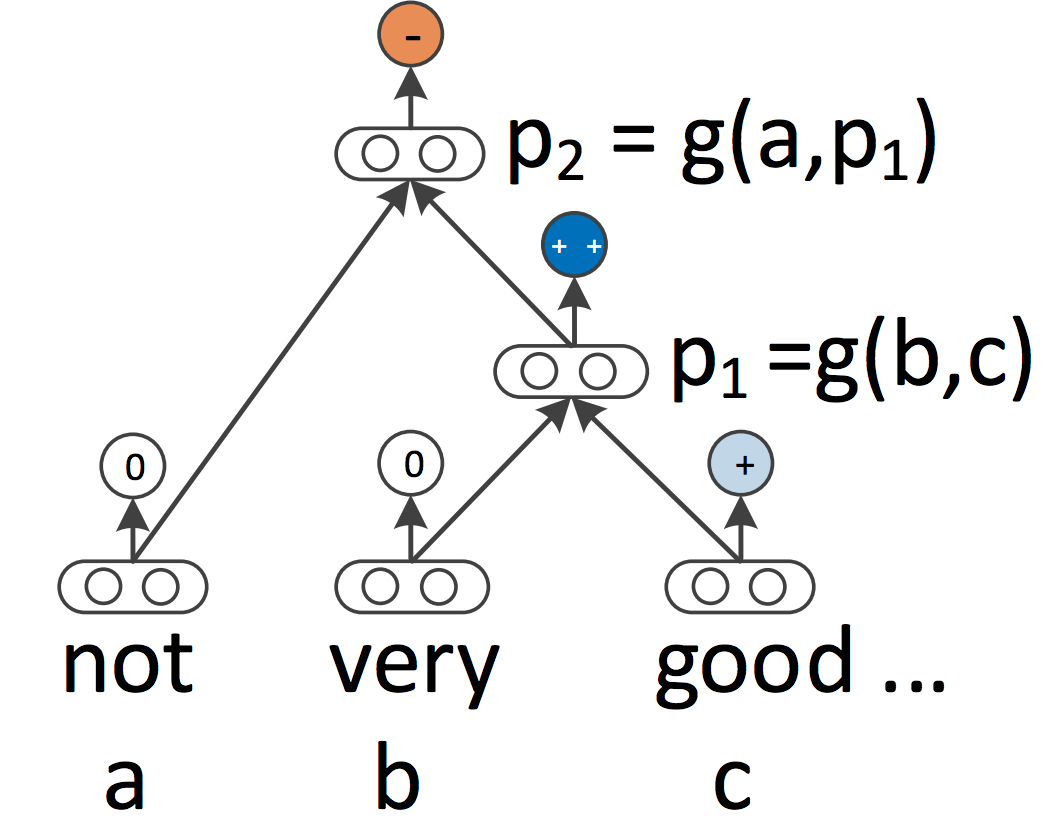
再帰的ニューラルネットワークは、文を左から右、または右から左に処理するRNNとは対照的に、下から上へと配列の表現を構築します。ツリーの各ノードでは、子ノードの表現を組み合わせて新しい表現が計算されます。このようなツリー構造によって、従来と異なる処理順序で文章の処理ができるため、RNNとLSTMは階層的な構造に拡張されてきました(Tai et al., 2015)。
RNNやLSTM以外のモデルにも、階層構造を扱うように拡張することができます。例えば、単語埋め込みは局所的だけでなく文法的な文脈に基づいて学習することができ(Levy & Goldberg, 2014)、言語モデルは構文スタックに基づいて単語を生成でき(Dyer et al., 2016)、グラフ進化型ニューラルネットワークは階層構造上でも動作することができます(Bastings et al., 2017)。
2014年 – sequence-to-sequenceモデル
2014年、Sutskeverらは、ニューラルネットワークを用いてある配列を別の配列にマッピングする一般的なフレームワーク、sequence-to-sequence learningを提案しました。
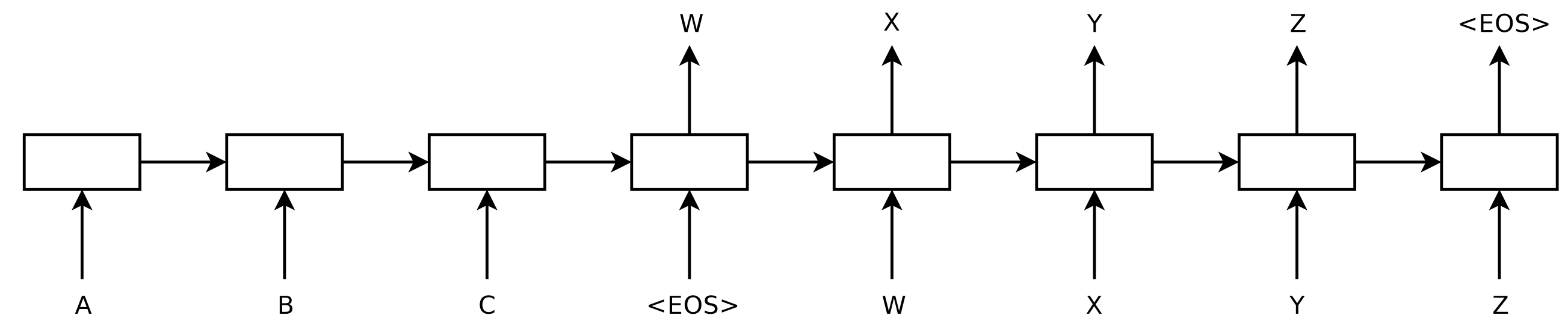
sequence-to-sequence learningでは、エンコーダーニューラルネットワークが文を記号ごとに処理してベクトル表現に圧縮します。
次にデコーダーニューラルネットワークが、以下の図8に見られるように、ステップごとに前に予測した記号を入力として、エンコーダー状態に基づいて出力を記号ごとに予測します。
そしてseqence-to-sequenceは、機械翻訳に対して非常に強力な手法であることが判明しました。2016年、Googleは従来のフレーズベースの機械翻訳モデルを、ニューラルネットを使った機械翻訳モデルに置き換え始めたと発表しました(Wu et al.,2016)。Jeff Deanによると、従来のフレーズベース機械翻訳モデルが50万行のコードで書かれたのに対し、ニューラルネットワークモデルは、たった500行のコードで書かれたと述べました。
その柔軟性からSeq2Seqは現在、自然言語生成タスクのためのフレームワークとして、エンコーダーデコーダーの役割を担う多様なモデルに適用されています。
そして重要なのは、デコーダーモデルはシーケンスだけでなく、任意の表現を条件とすることができる点です。これにより、例えば、画像に基づくキャプション生成(Vinyals et al., 2015)(以下の図9に見られるように)、表に基づくテキスト生成(Lebret et al., 2016)、ソースコードの変更に基づく記述(Loyola et al., 2017)など、幅広いNLPアプリケーションでテキストを生成することができます。
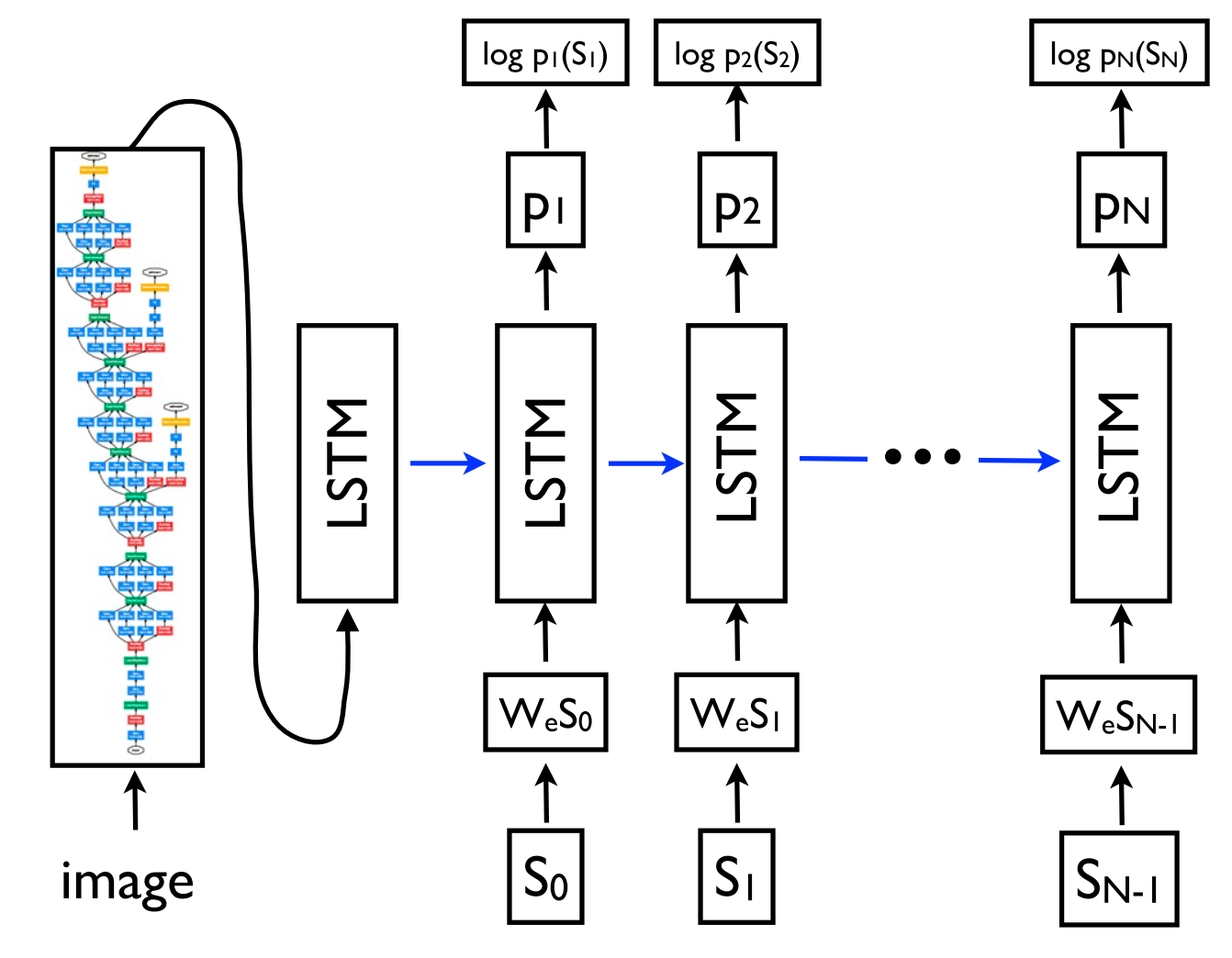
sequence-to-sequence learningは、出力が特定の構造を持つ、自然言語処理で一般的な構造予測タスクにも応用できます。簡単に説明すると、図10の構成要素解析のようにSeq2Seqの出力は線形化されます。ニューラルネットワークは特に、構成要素構文解析(constituency parsing)(Vinyals et al, 2015)と、固有表現抽出(named entity recognition:NER)(Gillick et al, 2016)において、十分な量の学習データがあれば、このような線形化されたテキスト生成を直接学習できることが研究で明らかになっています。
Seq2Seqのエンコーダーとデコーダーは通常、RNNに基づきますが、他のタイプのモデルでも使用できます。他のタイプの新しいsequence-to-sequenceアーキテクチャは、特に機械翻訳(MT)の分野で活発に開発されています。例えば、最近開発されたモデルには以下のようなものがあります。
- deep LSTMs(Wu et al., 2016)
- 畳み込みエンコーダー(convolutional encoders)(Kalchbrenner et al., 2016; Gehring et al., 2017)
- Transformer(Vaswani et al., 2017)
- LSTMとTransformerの組み合わせ(Chen et al., 2018)
関連記事|【図解】誰でもわかるTransformer入門!凄さ・仕組みをわかりやすく解説
2015年-Attention
Attention(Bahdanau et al., 2015)は、ニューラル機械翻訳(NMT)の主要な革新技術の1つであり、ニューラル機械翻訳モデルが古典的なフレーズベースの機械翻訳システムを凌駕することを可能にした重要な考えです。
従来のSeq2Seqの学習の主な問題点は、入力シーケンスの内容全体を固定サイズのベクトルに圧縮する必要があったことです。アテンションは、図11のように、デコーダーへの追加入力として加重平均として提供される入力シーケンスの隠れ状態をデコーダーが見返すことを可能にすることで、Seq2Seqの問題点を軽減しました。
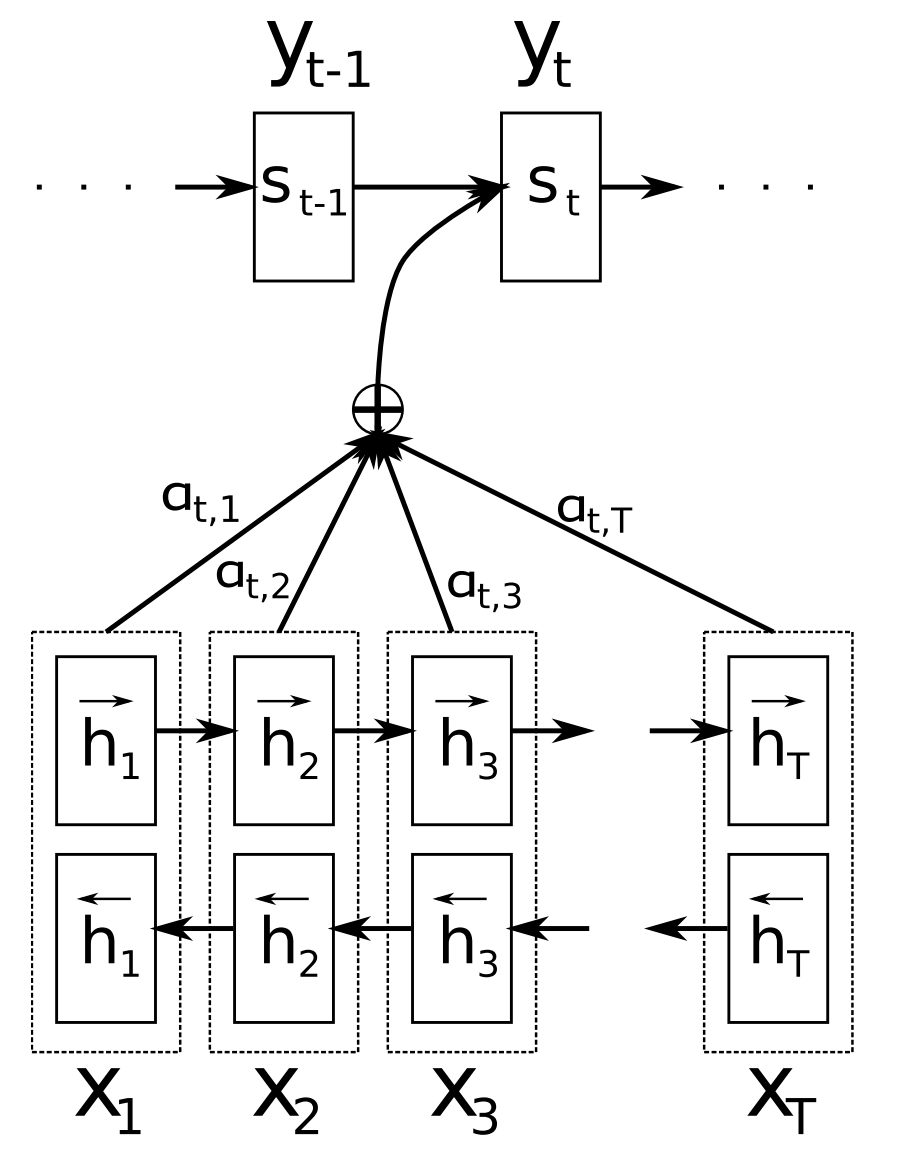
Attentionにはさまざまなタイプがあります(Luong et al.) 。Attentionは広い分野に適用可能で、入力の特定の部分に基づいて意思決定を行う様々なタスクに効果的だと考えられています。
例えば、Attentionは特に、構文解析(Vinyals et al., 2015)、読解(Hermann et al., 2015)、ワンショット学習(Vinyals et al., 2016)などに適用されています。また、入力としてシーケンス以外にも、画像キャプションの場合(Xu et al., 2015)のように、他の表現で構成することができ、これは以下の図12のように画像の重要な部分に注目(Attention)できます。
Attentionの有益な副次的効果は、Attentionの重みを調べることで、モデルが予測のために入力のどの部分を使用しているかを表面的にではあるものの、理解することができ、モデルの内部構造を垣間見ることができることです。

また、Attentionは入力列を見るだけに限定されず、self-attentionを用いて文や文書の周囲の単語を見ることで、より文脈に敏感な単語表現を得ることができる。自己注意の複数の層は、ニューラル機械翻訳の現在の最先端モデルである、Transformerアーキテクチャ(Vaswani et al.,2017)の中核をなしています。
関連記事|【図解】Attentionとは?わかりやすく、そして深く解説
2015年 – メモリベースのネットワーク(Memory-based networks)
Attentionは「曖昧な記憶(fuzzy memory)」の一形態と言え、記憶はモデルの過去の隠れた状態から構成され、モデルは記憶から何を取り出すかを選択します。Attentionの概要と記憶との関連については、こちらの記事をご覧ください。
こうした背景から、より明示的な記憶を持つ多くのモデルが提案されてきました。例えば、以下のような様々なモデルがあります。
- Neural Turing Machines (Graves et al., 2014)
- Memory Networks (Weston et al., 2015)
- End-to-end Memory Networks (Sukhbaatar et al., 2015)
- Dynamic Memory Networks (Kumar et al., 2015)
- Neural Differentiable Computer (Graves et al., 2016)
- Recurrent Entity Network (Henaff et al., 2017)
メモリは、しばしばAttentionと同様に現在の状態との類似性に基づいてアクセスされ、一般的に書き込んだり読み出したりすることができます。
モデルは、メモリをどのように実装し、活用するかで異なります。
例えば、End-to-end Memory Networksは、入力を複数回処理し、メモリを更新して複数段階の推論を可能にします。また、Neural Turing Machinesは、メモリ内の位置やインデックスに基づいたアドレス指定を持ち、並び替えのような単純なコンピュータプログラムを学習することができます。
メモリベースのモデルは、言語モデリングや読解のような、より長い時間にわたって情報を保持することが有用なタスクに適用されるのが一般的です。メモリという概念は非常に汎用的で、知識ベースやテーブルがメモリとして機能することもあれば、入力全体やその特定の部分に基づいてメモリを生成することもできます。
2018年 – 事前学習済み言語モデル(Pretrained Language models)
事前学習された単語埋め込みは文脈にとらわれず、モデルで第1層を初期化するためにのみ使用されます。ここ数ヶ月、様々な教師ありタスクが、ニューラルネットワークの事前学習に使用されています(Conneau et al., 2017; McCann et al., 2017; Subramanian et al., 2018)。
一方で、言語モデルはラベル付けされていないテキストを必要とするだけなので、学習は何十億ものトークン、新しいドメイン、新しい言語に拡張することができます。事前学習された言語モデルは2015年に初めて提案されました(Dai & Le, 2015)が、最近になって、多様なタスクで有益であることが報告されています。言語モデル埋め込みは、ターゲットモデルの特徴として使用することができ(Peters et al.,2018)、または言語モデルはターゲットタスクデータ上で微調整することができます(Ramachandran et al.,2017;Howard & Ruder、2018)。言語モデルの埋め込みを追加すると、以下の図13に見られるように、様々なタスクで、最先端技術(SOTA)に対する大きな改善が得られます。
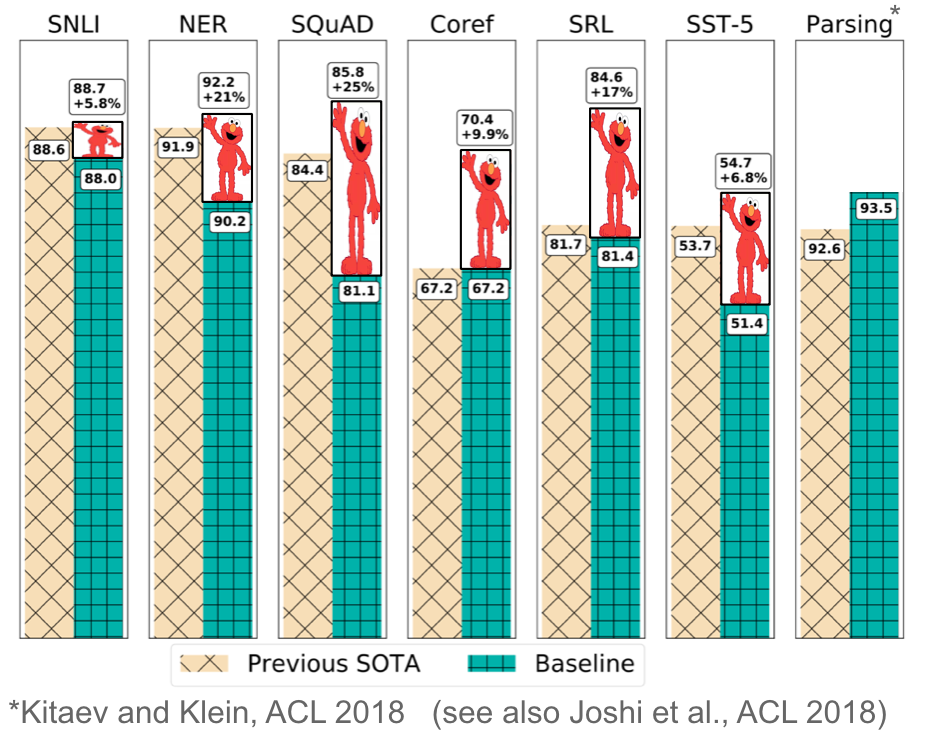
事前学習された言語モデルは、より少ないデータで学習できることが報告されています。言語モデルはラベルなしデータだけで学習できるため、ラベル付けされたデータが少ない低リソース言語には特に有効です。事前学習済み言語モデルの可能性については、こちらの記事を参照してください。
その他のマイルストーン
ここまで紹介したこと以外にも、上記ほどではないですが、NLPの分野に影響を与えたものを紹介します。
文字ベースの表現(Character-based representations)
CNNやLSTMを文字に適用して文字ベースの単語表現を得ることは、特に形態素の多い言語や形態素情報が重要なタスク、あるいは未知の単語が多いタスクでは、近年かなり一般的になっています。
この文字ベースの単語表現は、品詞タグ付けや言語モデリング(Ling et al.,2015)、依存性解析(Ballesteros et al.,2015)といった研究で初めて紹介されました。その後、シーケンスラベリング(Lample et al., 2016; Plank et al., 2016)および言語モデリング(Kim et al., 2016)のためのモデルの主要な構成要素になりました。
文字ベースの表現は、計算コストの増加で固定語彙(fixed vocabulary)を扱わなければならない必要性を軽減し、完全に文字ベースのニューラル機械翻訳(Ling et al., 2016; Lee et al., 2017)などのアプリケーションを可能にします。
敵対的学習(Adversarial learning)
敵対的学習は機械学習の分野に大きな影響を与え、NLPでも様々な形で応用されています。
敵対的用例(Adversarial examples)は、モデルの限界や失敗例を理解するためのツールとしてだけでなく、モデルをより堅牢にするためにも、機械学習研究においてますます広く使われるようになってきています(Jia & Liang, 2017)。
(仮想の)敵対的学習、またはworst-case perturbations(Miyato et al., 2017; Yasunaga et al., 2018)およびドメイン敵対的損失(Ganin et al., 2016; Kim et al., 2017)は、同様にモデルをより堅牢にすることができる有用な正則化の手法です。
生成的敵対ネットワーク(GAN)は、自然言語生成にはまだあまり有効ではないですが(Semeniuta et al.,2018)、分布をマッチングするときなどに有効な方法です(Conneau et al.,2018)。
強化学習(Reinforcement learning)
強化学習は、学習時のデータ選択(Fang et al., 2017; Wu et al., 2018)や対話のモデル化(Liu et al., 2018)など時間依存性を持つタスクに有効であることが示されています。
また、強化学習は、要約(Paulus et al, 2018; Celikyilmaz et al, 2018)や機械翻訳(Ranzato et al, 2016)におけるクロスエントロピーのような代替損失を最適化する代わりに、ROUGEやBLEUなどの非差別的エンドメトリックを直接最適化するのに有効です。
同様に、逆強化学習は、ビジュアルストーリーテリング(Wang et al., 2018)のような報酬が複雑すぎて指定できない設定でも有用です。
ニューラルネット以外のマイルストーン(Non-neural milestones)
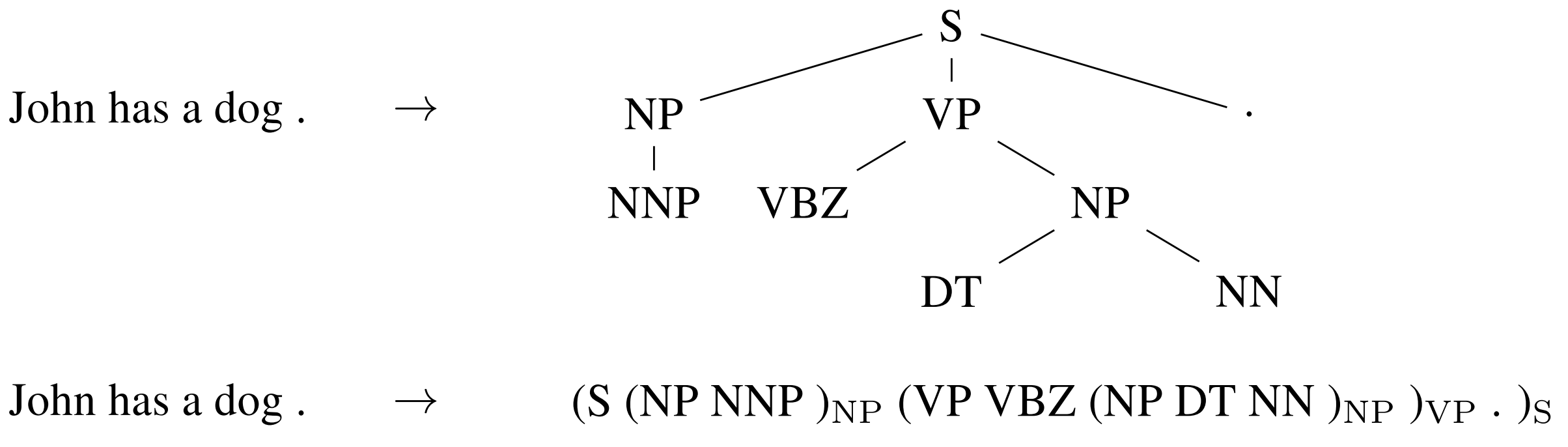
1998年から数年間はFrameNetプロジェクトが導入され(Baker et al., 1998)、現在でも活発に研究されている浅い意味解析の一形態である、セマンティックロールラベリング(semantic role labelling)というタスクが生まれました。
2000年代前半には、国際学会のConference on Natural Language Learning(CoNLL)Shared taskで、チャンキング(Tjong Kim Sang et al., 2000)、固有表現認識(Tjong Kim Sang et al., 2003)、依存解析(Buchholz et al., 2006)など、主要NLPタスクについての研究が活性化しました。CoNLL Shared taskで発表されたデータセットの多くは、現在でも評価の基準となっています。
2001年には、シーケンスラベリング手法の中で最も影響力のあるクラスの1つ、条件付き確率場(CRF; Lafferty et al., 2001)が発表され、ICML2011でTest-of-time賞を受賞しました。CRF層は、固有表現認識のようなラベルの相互依存性を伴うシーケンスラベリング問題に対する現在の最先端モデルの中核をなしている(Lample et al.,2016)。
2002年、機械学習システムのスケールアップを可能にする評価指標、BLEU(Papineni et al., 2002)が提案され、現在も機械学習の標準的な評価指標として使用されています。同年、構造化プリセプトロン(the structured preceptron)(Collins, 2002)が発表され、構造化知覚の研究の基礎が作られました。また同じ会議で、最も人気があり広く研究されているNLPタスクの1つである、感情分析が紹介されました(Pang et al., 2002)。NAACL 2018では、3つの論文すべてがTest-of-time賞を受賞しました。さらに、同年には言語資源として、PropBank (Kingsbury & Palmer, 2002) が開発されました。PropBankはFrameNetに似ていますが、より動詞に特化しており、意味役割付与に多く利用されています。
2003年には、機械学習で最も広く使われている手法の1つであるLDA(latent dirichlet allocation; Blei et al.2003)が導入され、現在でもトピックモデリングの標準的な方法として用いられています。2004年には、SVM (Support Vector Machine)よりも構造化データの相関を捉えるのに適した、新しいmax-marginモデルが提案されました(Taskar et al., 2004a; 2004b)。
2006年には、複数のアノテーションと高いアノテーション間一致率を持つ大規模な多言語コーパス、OntoNotes (Hovy et al., 2006)が発表されました。OntoNotesは、係り受け解析や共参照解決など、様々なタスクの学習や評価に利用されています。Milne and Witten (2008)は2008年にWikipediaを利用して機械学習の手法を充実させる方法を説明しました。今日に至るまで、Wikipediaはエンティティリンクや曖昧性解消、言語モデリング、知識ベース、その他様々なタスクなど、ML手法の学習に最も有用なリソースの1つとなっています。
2009年、遠隔監視(distant supervision)が提案されました(Mintz et al., 2009)。遠隔監視は、ヒューリスティックや既存の知識ベースからの情報を活用し、大規模なコーパスから自動的に用例を抽出するために使用できるノイズの多いパターンを生成します。遠隔監視は広範囲に利用されており、関係性抽出、情報抽出、センチメント分析などのタスクで一般的な技術です。
2016年には、多言語ツリーバンクのコレクションであるUniversal Dependencies v1 (Nivre et al., 2016)が発表された。Universal Dependenciesプロジェクトは、多くの言語間で一貫性のある依存関係ベースのアノテーションを作成することを目的としたオープンコミュニティの取り組みです。2019年1月現在、Universal Dependencies v2は70以上の言語の100以上のツリーバンクで構成されています。
謝辞
ニューラルネットワークを用いた自然言語処理分野の歴史をまとめた本記事の原文には、こちらからアクセスできます。この記事の続編(英語)はこちら。この投稿の元となった講演の録音は、こちらでご覧いただけます。
この網羅的で素晴らしいレビューを投稿し、日本語への翻訳をサポートしてくださったSebastian Ruder氏に感謝します。
Thanks to Sebastian Ruder for this exhaustive and excellent review and for his assistance in translating it into Japanese.
著者について
著者:Sebastian Ruder
翻訳・翻案:すえつぐ
早稲田大学でNLPについて研究。ドイツの名門・ミュンヘン工科大学に留学し、DeepLearningを学ぶ。留学をきっかけに当ブログを開始。
監修:末次 章
2000年〜現在までスタッフネット株式会社代表。
モダンWeb・Angularに関する技術書籍、専門雑誌、記事を多数執筆(著作物一覧)。