
こんにちは!自然言語処理(NLP)・大規模言語モデル(LLM)の解説記事や書籍を書いている、
すえつぐです!
お知らせ:著書 『誰でもわかる大規模言語モデル入門』 を日経BPより出版しました。
ニューラルネットワークを構成する重要な要素の一つ、「活性化関数」。近年では自然言語のモデルにもニューラルネットワークが頻繁に使用されており、活性化関数を理解することは必須になっています。
一方で、活性化関数について詳しく説明されているサイトはあまりありません。活性化関数をなんとなく知っているという方も「なぜ活性化関数が必要なのか?」と聞かれると困りませんか?
そこで今回は「活性化関数って何?そもそも活性関数はなぜ必要なのか?」という皆さんの疑問を解決していきます!活性化関数をわかりやすく、深く解説していきます!
図解で活性化関数をわかりやすく解説
ここでは、「活性化関数とは。ニューラルネットワークにおける役割」、「一次関数と活性化関数でできている理由」、「活性化関数の仕組みと具体例」についてイラストを使ってわかりやすく解説していきます!
活性化関数とは。ニューラルネットワークにおける役割
そもそも活性化関数とはなんなのか?について、数式を使わずに解説していきます。
活性化関数とは、一文で説明すると「ニューラルネットワークの隠れ層のニューロンを構成する要素の一つ。」です。
言葉だけだと難しく感じるかもしれませんが、下のイラストを見てみてください。
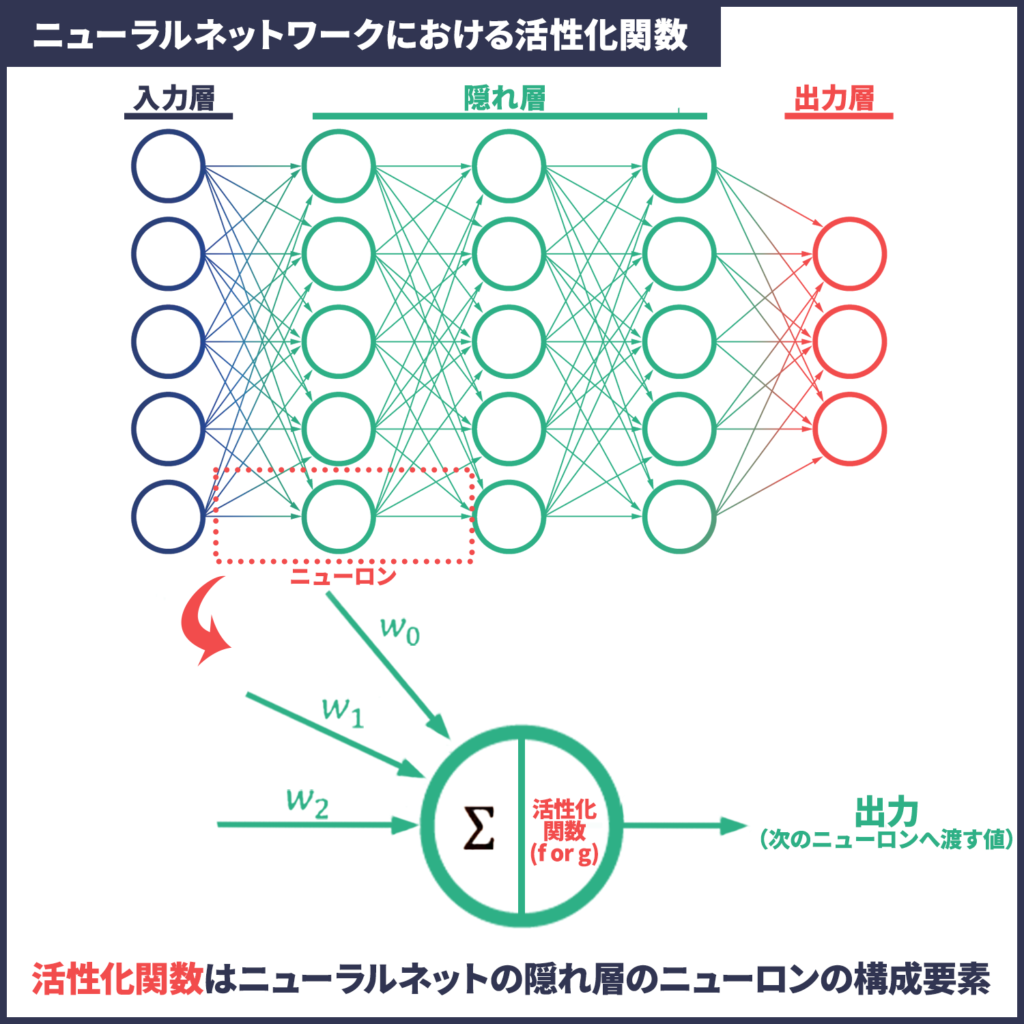
イラストの上部、ニューラルネットの図は見たことがある人も多いのではないでしょうか?このニューラルネットの隠れ層を構成している要素がニューロンです。さらにそのニューロンを構成する一部分が活性化関数なのです。
次に「Σ」と「w」について超簡単に説明すると、これらは「一次関数」です。一次関数と言えば、中学で習った「y = ax+b」です。ざっくり説明すると、「ax+b(一次関数」と「活性化関数」でできているのがニューロンなのです。
つまり、ニューラルネットを構成するニューロンの一つ一つは「一次関数と活性化関数の組み合わせ」でできています。
ニューラルネットワーク、ディープラーニングと聞くと複雑そうなイメージを持っていると思います。しかし、一つ一つを見ていくと非常にシンプルな仕組み(関数)なのです。
ではなぜシンプルなのに、人間を超えるような高精度を実現しているのでしょうか?
それは「シンプルなニューロンを大量に組み合わせているから」です。つまり、シンプルなニューロンを大量に組み合わせることで複雑な関数を作り、高精度を実現しているのがディープラーニングと言えます。
そしてそのニューロンを構成している「一次関数と活性化関数」について、もう少し詳しく解説していきます。
一次関数と活性化関数で構成される理由
さて、ここまでで「ニューロンは一次関数と活性化関数の組み合わせ」ということがわかっていただけたと思います。では、なぜ活性化関数が必要なのでしょうか?一次関数だけではダメなのでしょうか?
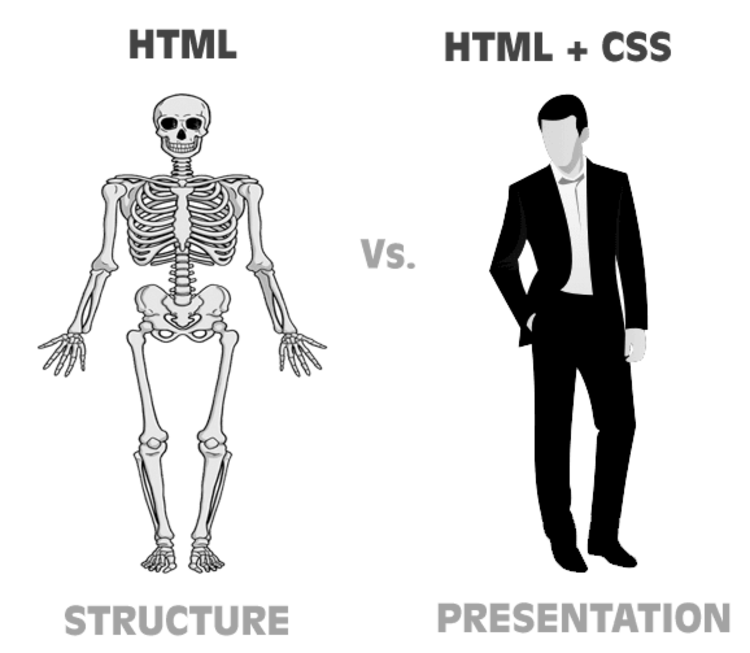
この答えは、「一次関数は計算量が小さいという強みを持っているが、一次関数だけだとシンプルすぎるモデルしかできない」からです。一次関数は線形で、この線形を何度も掛け合わせても線形にしかならず、複雑な関数を作ることができません。そこに表現力を加えるのが活性化関数なのです(下イラスト)。

上のイラストを見るとわかるように、一次関数だけの場合は単純な関数しか作れず、複雑なデータに対応することができません。活性化関数と組み合わせることで、複雑な関数を作ることができるようになるのです。
Webプログラミングがわかる方であれば一次関数がHTML、活性化関数がCSSというイメージを持つとわかりやすいかもしれません。HTML(一次関数)だけだと、どう工夫してもシンプルすぎるものにしかなりませんよね。そこにCSS(活性化関数)を加えることで、必要とする複雑なものも作れるようになるのです。
実際に、活性化関数が必要な理由は「一次関数に表現力を与える」とよく説明されます。これもHTMLとCSSをイメージするとわかりやすいのではないでしょうか。
活性化関数の仕組みと具体例
活性化関数を使う理由がわかったところで、活性化関数の仕組みと良く使われる関数を見ていきましょう。
活性化関数の仕組みは基本的に、「入力(一次関数の計算結果)が、小さければ0に近い値、大きければ1に近い値」を出力します。
さっそく具体的な関数を見て確認していきましょう。
代表的な活性化関数「Logistic sigmoid関数」から、現在も使われている活性化関数「ReLU」までを網羅的に見ていきます。
ロジスティックシグモイド関数(SIGMOID)
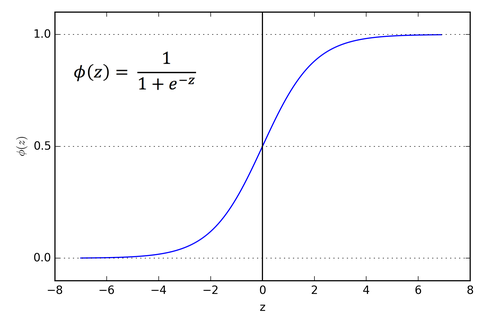
ロジスティックシグモイド関数は代表的な活性化関数です。自然言語のモデルでも使用され、RNNLMなどに使用されています。
*ロジスティックシグモイド関数は単に「シグモイド関数」と呼ばれることもあります。
グラフを見ると「入力が小さければ0、大きければ1に近い値を出力する」が行われていることがわかります。入力が-4以下であればほぼ0、4よりも大きければほぼ1を出力します。
ただ、シグモイド関数は実際のモデルではほとんど使われなくなりました。その理由は主に3つあり、それぞれを改善した関数が作られています。
①ゼロ中心ではない。(x=0の時、y=0.5)
→ハイパブリックタンジェント関数によって改善。
②勾配消失を引き起こす。
→ReLU関数によって改善。
③計算量が多い
→ReLU関数によって改善。
このように、ロジスティックシグモイド関数を改善した関数である、「ハイパブリックタンジェント関数」と「ReLU関数」についても解説していきます。
ハイパブリックタンジェント関数(TANH)
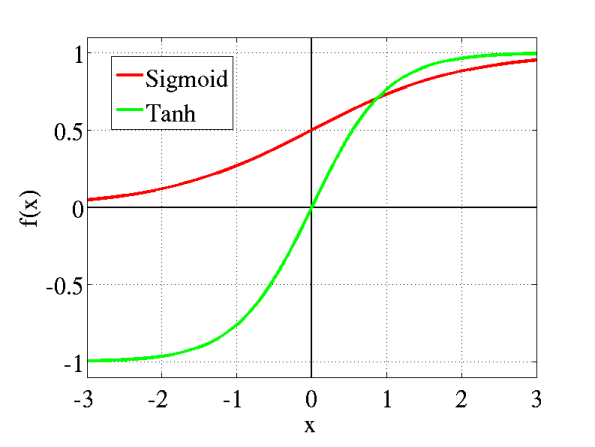
前述しましたが、ハイパブリックタンジェント関数はロジスティックシグモイド関数の「0中心ではない」という欠点を改善しました。上のグラフを見ると、シグモイド関数が縦に拡張され0中心になっていることが分かります。
一方で、「勾配消失を引き起こす」と「計算量が多い」という問題点は改善されていません。これらの問題点も解決したのが「ReLU関数」です。
RELU関数
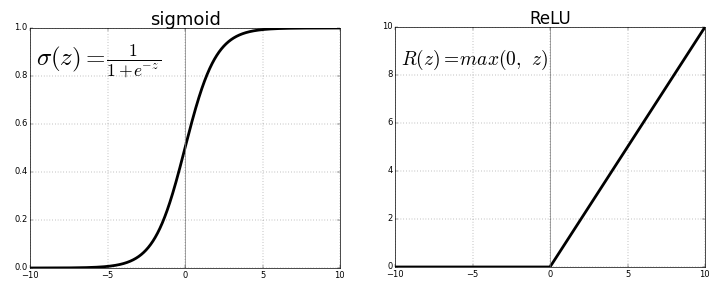
ReLU関数は、勾配消失が起こらず、計算量が小さいという2つの点から現在でも広く使われています。特に畳み込みニューラルネットワークで広く使用されている活性化関数です。
「xが0以下であれば0、0より大きければその値を返す」という非常にシンプルな関数のため、計算量が非常に小さいのも大きな長所です。
ReLU関数が非常にシンプルなことに驚いた人も多いのでしょうか。感覚的には改善された関数ほど、複雑になっていきそうですよね。
活性化関数がシンプルな理由は「一つ一つのニューロンの計算量を小さくできれば全体の計算量を大きく軽減できるから」です。
前提としてニューラルネットワークには膨大な数のニューロンで構成されています。それの一つ一つが今回見る「一次関数と活性化関数の組み合わせ」でした。
この一つ一つの計算量が少しでも上がると、全体の計算量が膨大に増加します。そのため、計算量を抑えながら表現力を出すことができるReLU関数のようなシンプルなものが採用されているのです。
*実際には計算量が大きくなることを受け入れて、ReLU関数を若干複雑にしたLeaky ReLU関数などを使う場合もあります。
Softmax関数
softmax関数はここまで紹介した関数とは少し用途が異なります。Tanh関数やReLU関数が主にニューラルネットの隠れ層(中間層)で使われるのに対して、softmax関数は主にニューラルネットの出力層で使用されます。(冒頭で紹介した図の出力層に当たります)

特にsoftmaxが使われる場面としては、「分類問題の最終層」として多くの場面で多用されています。
softmax関数の仕組み
softmax関数を一文で説明すると、「合計が1になる0-1の値に入力値を変換する関数」です。これだけだとわかりづらいと思うので、実際に数値がどう変換されるかを見てみましょう。

イラストのように、[5, 4, -1]が入力値の場合を考えてみます。受け取った入力値を、「0−1の値、合計が1」の出力値に変換するのがSOFTMAX関数です。今回は入力値の[5, 4, -1]が、[0.730, 0.268, 0.002]に変換されていることがわかります。合計が1、0-1の確率値に変換されたことがわかります。

イラストのように、AIは出力値に[猫:5, ネコ:4, 陰口を聞く女:-1]のような数値を出します。
softmaxを使わない場合、人間には「どのくらいの確率なのか」ということがわかりづらいです。「和訳の答えは、猫の確率が5で、陰口を聞く女の確率は-1です!」と言われたら混乱しますよね。
一方で、softmaxを使えば「合計が1になるような0-1の値」に変換されるため、直感的に非常にわかりやすくなります。イラストのように、「猫の確率が73%で、陰口を聞く女の確率は0.2%です」と言われれば非常にわかりやすいですよね。
言うなればsoftmaxは「AIと人の間の通訳」のようなイメージです。実際に、Softmax関数はAIが出した出力値を最後に変換する「最終層」で使われることがほとんどです。
もし論文やまとめサイトで「〜の結果をsoftmaxする」と言われたら、「〜の結果を、わかりやすい確率値に変換してるんだな」と理解すれば大丈夫です。
Softmax関数に関する数式の詳細などは以下の記事でより詳しく解説しています。

まとめ
- ニューラルネットの最小単位、ニューロンは「一時関数と活性化関数の組み合わせ」。
- 一次関数と活性化関数を組み合わせることで、小さい計算量で複雑な関数を作ることができる。
参考資料・おすすめの参考書
ここまでの学習、お疲れさまでした。そして本記事を最後まで読んでいただきありがとうございました!
ここからは、おすすめの書籍を紹介します。この記事で興味を持った方は、本を読めばさらに実践的な力が手に入るはずです。
特徴
・LLMの仕組みを、数式を使わず図で解説
・LLMを使った自動化をPythonコードで実装
今からLLMを体系的に学びたい、LLMを使った自動化や新機能を実装してみたいという方におすすめです。
以下のAmazon概要欄にて本の一部が無料で公開されていますので、ぜひ覗いてみてください。

活性化関数を含む、ディープラーニングをより詳しく学びたい方は、以下の書籍で詳細を学び、実装してみるのがおすすめです。



動画・オンラインコースで学びたい、機械学習からディープラーニングまでを網羅的に学びたい、復習したいという方には以下のUdemyがおすすめです。
【世界で55万人が受講】データサイエンティストを目指すあなたへ〜データサイエンス25時間ブートキャンプ〜 ![]()
このUdemyのコースは統計学・数学から機械学習・ディープラーニングまでの広い範囲を、非常にわかりやすくまとめた入門コースです。
勉強・復習に便利なのはもちろん、私はチームで共通認識を作るためにチーム全員でこのコースを購入しました。
自然言語処理のおすすめ書籍・オンラインコースはこのページでまとめて紹介しています。
「NLPを最短で体系的に学びたい」という方のために、テーマごとに厳選した書籍、そもそもNLPは何から学べば良いか?などを網羅的にまとめています。是非ご覧ください。
おすすめの勉強ステップ
1. 概要・大枠を知る。
Webサイトなどで概要を理解する(本サイトはこのステップの支援を目指しています。)
詳細を学ぶ際に、より効率良くインプットできる。
2. 詳細を知る、理解を深める。
書籍、論文でより詳しく学ぶ。
3. 実践・アウトプット
SignateやKaggleに参加してモデルを作ってみる、勉強したことをブログにまとめる。
関連記事|【完全マニュアル】技術ブログを始めるべき理由と始め方。メリット・収益・書き方を徹底解説
個人的には、データサイエンス、特にNLP関係の本は難しく、いきなり本を読むと挫折してしまう人が多いと感じています。
このサイトで概要・全体像を理解してから本を読むことで、より理解しやすく挫折も少なくなるはずです。(その役に立てるよう記事を執筆していきます!)