
Attention” is often used in NLP libraries, is considered a breakthrough in natural language processing, and is essential for understanding cutting-edge technologies such as BERT and GPT-3.
On this page, we would like to explain “Attention” in an in-depth and easy-to-understand.
Table of Contents
- What is Attention?
- Why it is called a breakthrough in the natural language world
- A profound explanation of how Attention works with mathematical formulas based on the original paper
- 1.1 What is ATTENTION?
- 1.2 Why ATTENTION is considered a breakthrough in the natural language world
- 2. a profound explanation of how ATTENTION works with mathematical formulas based on the original paper
- 2.1 Overall flow of ATTENTION
- 2.2 Important formula in ATTENTION: Understanding the context vector (CI) with mathematical formulas
- Summary of Chapter 2
- Conclusion.
1.1 What is ATTENTION?
Attention is a mechanism that tells AI which words in a sentence are essential for a task and which words to pay Attention (Attention) to when performing the task. The development of Attention overcame the fatal flaw of the previous model, which was inaccurate for longer sentences.
Since Attention is very close to the human way of thinking and is intuitively easy to understand, let’s understand it with a concrete example.
For example, suppose you have a task to translate English into Spanish, as shown in the sentence below.
English sentence
Emily was born and raised on an apple farm, so she ate apples every day, and of course, Emily loves apples.
Translated sentence
Emily nació y creció en una granja de manzanas, por lo que comía manzanas todos los días, y por supuesto, a Emily le ( ) las manzanas.
Of course, the answer is “encantan”. How did you translate it in your mind?
“Emily loves” is the part to be translated, so “encantan” is the word to be translated.
You probably came up with “encantan” in this way. In this translation, “Emily loves apples.
If you think, “To translate, just the part “Emily likes apples” is enough.” then you are very wise. That is a critical point of Attention.
Attention is what makes AI understand what humans do unconsciously, “This part is important for this translation”. Just as you felt just now.
Let’s compare the conventional method and the Attention model as illustrated below.
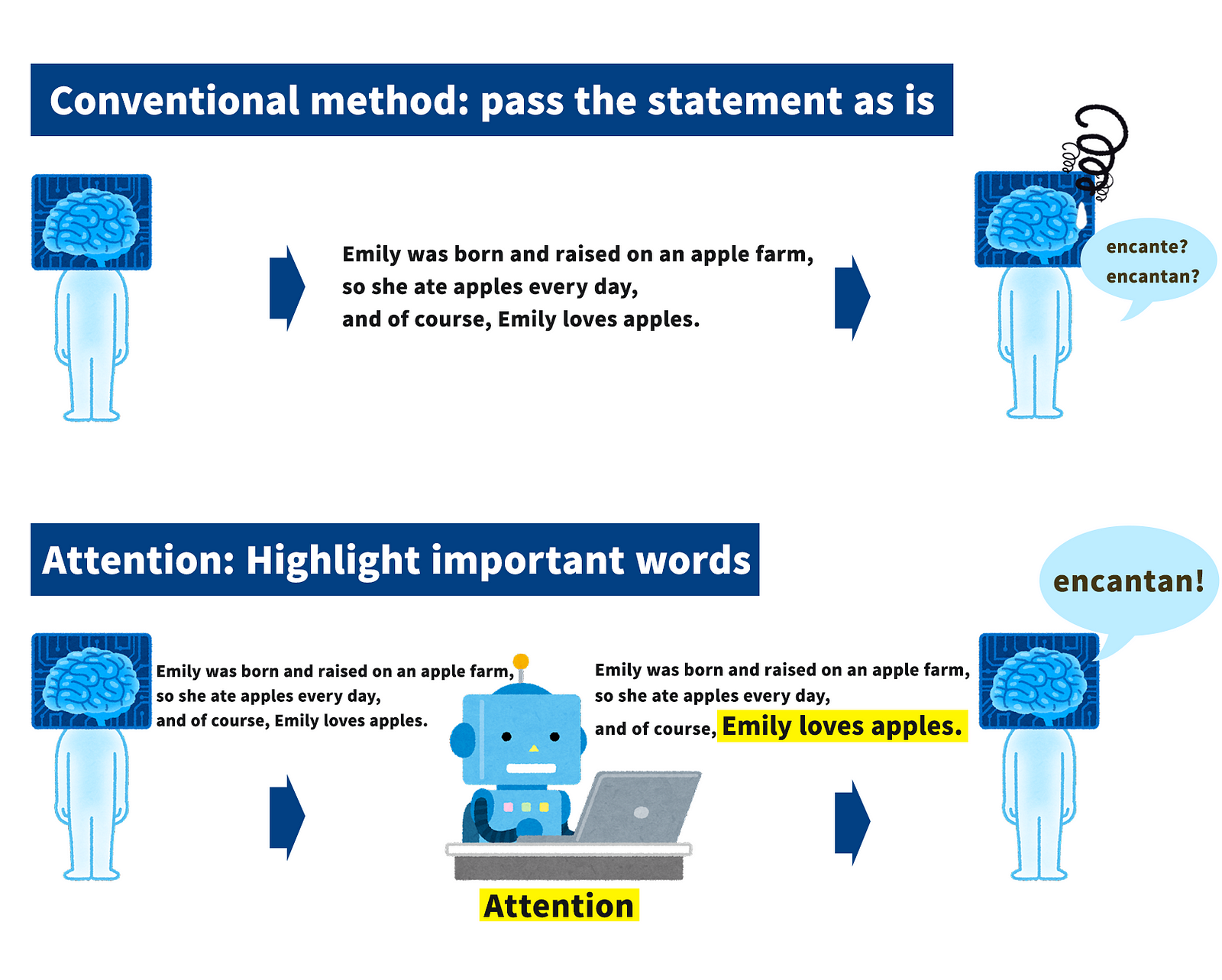
As shown in the illustration, the conventional method passes sentences as they are. If the sentence is short, it can be translated accurately, but if the sentence is long, as in this case, the accuracy will be degraded. In the paper, it was pointed out that the accuracy of the conventional method drops sharply after 30 characters.
On the other hand, Attention highlights essential words such as “Emily” and “I like. This allows the reader to focus on the critical words (Attention) and thus enables accurate translation even of long sentences.
Summary of key points
- Attention is a mechanism that tells the AI which words are important and should be paid attention to for the task.
- Thanks to this mechanism, accuracy is not compromised even in long sentences.
1.2 Why ATTENTION is considered a breakthrough in the natural language world
The reason why Attention is considered a breakthrough in the natural language world is that it is an important mechanism that leads to BERT, GPT-3, and other state-of-the-art libraries.
Attention was announced in 2015. From there, the natural language processing world has developed rapidly.
Two years after Attention was published, Transformer, built on Attention, was published. Transformer’s paper title was “Attention Is All You Need,” and proposed a model using only Attention.
As many of you may know, the Transformer was the basis for the creation of powerful libraries such as BERT and GPT-3.
Attention is at the root of the rapid development of NLP in recent years. Concentration is therefore considered a breakthrough in the natural language world.
The development of the natural language world may be easily understood by comparing it to the process in which the means of transportation developed from horse-drawn carriages to cars.
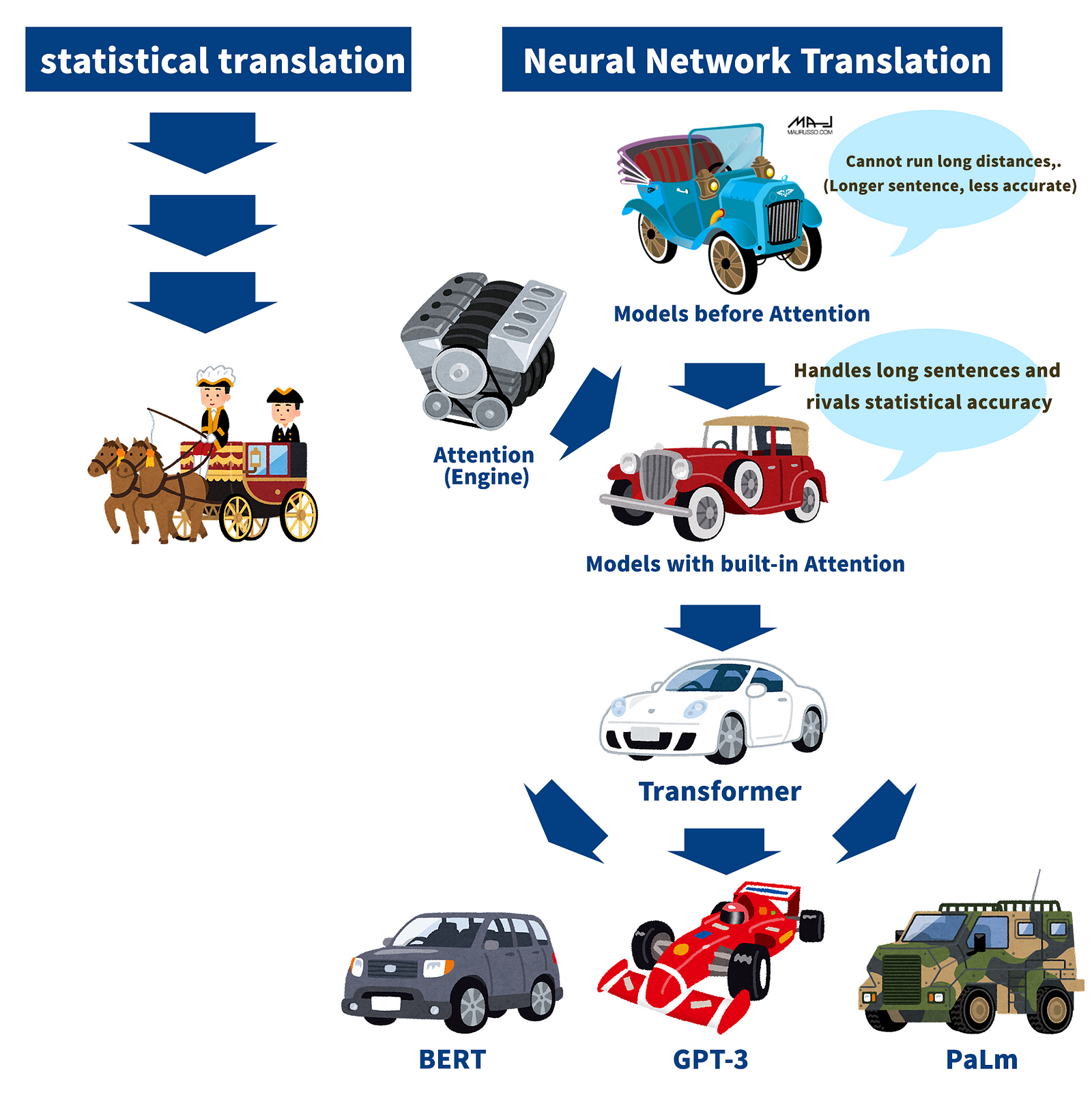
The pre-Attention model had the disadvantage of not being able to handle long sentences, but this was overcome by incorporating a new Attention mechanism. Furthermore, it demonstrated the same level of translation accuracy as statistical translation, which had been the predominant translation method up to that point.
Based on Attention, Transformer was developed a few years later.
Various powerful models incorporating Transformers were created. These powerful models are the ones we usually use, such as BERT, GPT-3, and PaLm.
Summary of key points from Chapter 1
Attention is a mechanism that tells AI “which words are essential for that task. This mechanism’s accuracy is no longer compromised even with long sentences.
Attention is called a breakthrough in the natural language world because Attention is at the root of the rapid development of NLP in recent years.
2. a profound explanation of how ATTENTION works with mathematical formulas based on the original paper
Now that you have understood the outline of ATTENTION let me explain how ATTENTION works.
From this point on, we will explain the formulas important for understanding Attention based on the original paper. Of course, this chapter is a bit difficult to understand, but even those who do not have a background in mathematics can understand it. (Those who say that just an overview is enough are fine up to here. Don’t forget to follow, clap.)
If you can read and understand this chapter thoroughly, you should be able to understand and explain Attention in mathematical formulas.
If you plan to read the original paper for research or other purposes, reading this chapter before reading the original report will enable you to understand the general contents and read the original article smoothly.
The flow of the chapter will be explained as follows.
2.1 Explanation of the overall flow
2.2 Explanation focusing on the vital part of Attention
If you understand this chapter, you can understand and explain Attention by formula.
2.1 Overall flow of ATTENTION
First, we will explain the Attention and the overall flow of the Attention.
The model introduced in the original paper that incorporates Attention is called “RNNsearch.” This model is based on the simple Encoder-Decoder model of the previous study, “RNN Encoder-Decoder.”
In other words, RNNsearch is a model that improves on the RNN Encoder-Decoder model but adds Attention.
Attention itself is not a model; Attention is a mechanism (architecture), and RNNsearch is a model that incorporates Attention.
Encoder: Converts input sentences, words, etc., into something AI can process.
Decoder: Processes and outputs the converted values.
From here, we will explain Attention’s model separately for Encoder and Decoder, comparing it with previous research. (We will use the same translation task as in the original paper)
Prior work: RNN Encoder-Decoder
Encoder Convert input word (x) into a with RNN.
Decoder Output word (p(yi)) by RNN with input semantic vector , hidden layer (Si), and previous word (yi-1)
Encoder
Convert input (x) into a word vector (hi) with BiRNN (bi-directional RNN), taking into account the previous and next context
The original paper’s word vector (hi) is called an annotation.
Decoder
Converts word vector (hi) to context vector (ci) using the Attention mechanism. The Decoder Attention mechanism converts the word vector (hi) into a context vector (ci) and weights (α) which words should be paid Attention (Attention). This is Attention.
Adapted from the original paper
Using the context vector (ci), hidden layer (Si), and previous words (yi-1) as input, RNN outputs word probability (p(yi))
In summary, prior research created a semantic vector © of the same fixed dimension for all words and used it directly in the RNN.
In contrast, the Attention model creates a context vector (ci) for each word, taking into account which words to focus on, and uses it in the RNN.
By changing the semantic vector to the context vector (ci), we overcame the problem of “accuracy drops with longer sentences,” which had been an issue until then.
The next chapter will explain this context vector (ci) with mathematical formulas.
2.2 Important formula in ATTENTION: Understanding the context vector (CI) with mathematical formulas
As explained in the previous section, we will explain the formula for obtaining the context vector (ci), which is the key to ATTENTION.
First, we will organize the role of each coefficient.
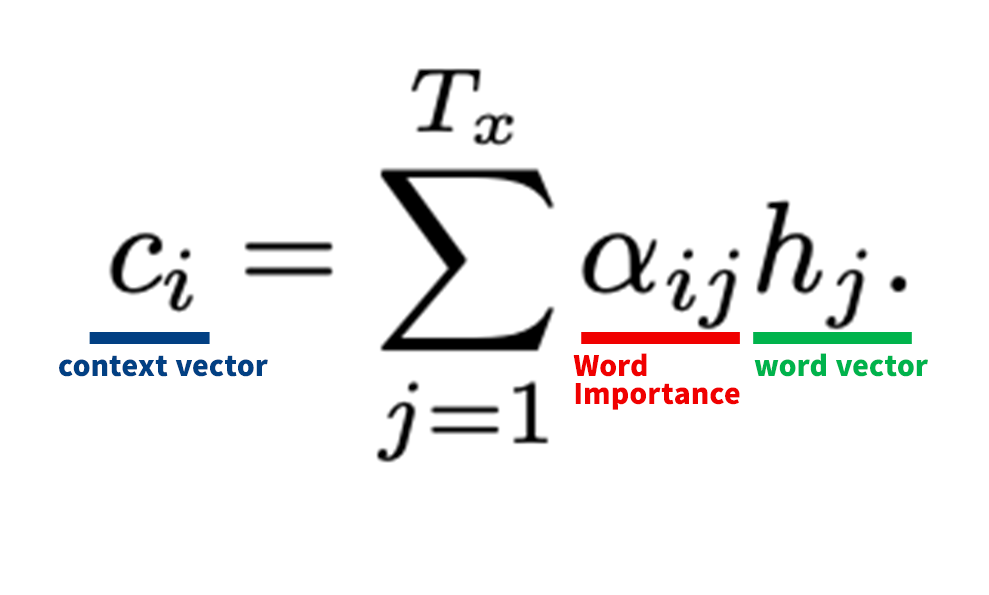
ci: context vector
It takes into account the context and contains information about “which words are important for the task. In the case of translation, it contains the information that “subject” and “like” are important to translate “I like.”
αij: Word importance
Weight indicates how important the word is to the task, with values ranging from 0 to 1. See below for details.
hj: Word vector
A vector that contains information not only about the word but also about the words before and after it, using Encoder’s bi-directional RNN.
In other words, to find the context vector (ci)
The word vector (hj) is weighted by the importance of the word (αij), and the sum of the weighted values (Σ) is produced.
This is what it means.
Supplement: Explanation of the formula for αij (word importance)
As a supplement, we will also briefly explain αij. The procedure for αij is as follows.
This is a softmax formula, so you can see that eij is calculated using softmax.
The eij is then used to calculate the hidden layer (Si-1) and the word vector (hj) to give a “score of how well the input around word j and the output of word i match.
If you would like to learn more about the eij formula and other details, please read the original paper (the link is attached at the bottom).
Summary of Chapter 2
- We improved the previous model (RNN Encoder-Decoder) and added an Attention mechanism.
- While the conventional model uses the same semantic vector © for each word, Attention uses a context vector (ci) for each word.
- The context vector (ci) is a word-weighted importance vector (α).
Conclusion.
Attention is a mechanism that tells AI “which words are essential for the task. Thanks to this mechanism, accuracy does not drop even in long sentences.
Attention is called a breakthrough in the natural language world because Attention is at the root of the rapid development of NLP in recent years.
While conventionally, the same semantic vector © is used for each word, Attention uses a context vector (ci).
The context vector (ci) is a weighting of importance by α for each word.
Thank you for reading! Please clap and follow me! I write about NLP in an easy-to-understand and illustrated way!
References and Reference Materials
Original Paper
Neural Machine Translation by Jointly Learning to Align and Translate